
AI can now draft more content than most teams can reasonably inspect. That is the first operational problem with human in the loop AI publishing: the content machine gets faster than the editorial system around it.
Teams think the problem is generation quality. The real problem is workflow control.
If every draft needs a senior editor, automation collapses under its own volume. If no draft needs review, the brand becomes a live testing environment. Neither model scales. The practical question is not whether humans should review AI content. The practical question is where humans should sit in the publishing system, what they should approve, and what the machine should learn from every decision.
In 2026, this matters because creators, publishers, and marketing teams are no longer experimenting with one-off AI drafts. They are building content engines: blogs, newsletters, podcasts, social snippets, persona-led sites, and niche media networks. Human in the loop AI publishing is not a definition. It is an architecture decision.
Table of contents
- Why human in the loop AI publishing is an architecture problem
- The publishing pipeline you are actually designing
- Define human review as routing, not heroics
- Quality gates that catch problems before publication
- Workflow automation without blind autopublishing
- Metrics that prove the loop is working
- What breaks when teams implement it badly
- What works in production
- Team operating model for creators and publishers
- Where bl0ggers.com fits
Why human in the loop AI publishing is an architecture problem
Human in the loop AI publishing sounds like an editorial principle. In practice, it is a systems design problem.
You are deciding how ideas become briefs, how drafts become review items, how approvals are logged, how errors are corrected, and how publishing states move across blogs, newsletters, podcasts, and social channels. If that system is vague, the team compensates with meetings, Slack threads, manual copy-paste, and last-minute rewrites.
A useful way to think about it is this: AI increases content supply. Human review must increase decision quality without becoming a manual bottleneck.
The surface problem is output
Most teams start with the obvious pain: they can produce more drafts. A founder can generate ten article outlines before breakfast. A marketing manager can spin up landing page variants. A creator can turn a podcast transcript into a newsletter, a blog post, and five short-form posts.
That looks like leverage until the drafts pile up. Then someone has to decide:
- Is this accurate enough to publish?
- Does this match our point of view?
- Is this too similar to something we already shipped?
- Does it need a subject matter expert?
- Which channel should receive it first?
- Who owns the final decision?
The mistake teams make is treating every draft as equal. They create one review queue, route everything to the same person, and wonder why AI did not save time.
The real problem is control
The real problem is not that AI drafts need review. The real problem is that the organization does not have clear controls.
Controls are not bureaucracy. In publishing, controls are the operating rules that protect quality while allowing throughput. They define which content can move quickly, which content must slow down, and which content should never be generated without a human brief.
Practical rule: Do not ask whether content is AI-generated. Ask what risk class it belongs to, who owns approval, and what evidence is needed before release.
That changes the conversation. Instead of debating AI in abstract terms, the team designs a pipeline.
Why 2026 makes this urgent
AI publishing is moving from tool usage to production infrastructure. Teams are connecting research agents, CMS systems, newsletters, audio generation, analytics, and monetization flows. The UI is not the whole system anymore.
For adjacent reading from our network, teams using AI publishing for local coordination face similar trust and routing issues in community workflows: Related reading from our network: AI publishing community building.
In this environment, human in the loop AI publishing is not about slowing down the machine. It is about designing where judgment enters the workflow so the machine can move safely.
The publishing pipeline you are actually designing
Human review works only when the upstream and downstream steps are explicit. If the team has not defined intake, generation, review, and release, the human reviewer becomes a catch-all error handler.
The pipeline should be boring. Boring systems are easier to debug.
Intake
Intake is where content work becomes structured enough for automation. A weak intake process produces vague prompts, inconsistent positioning, and drafts that need heavy cleanup.
A strong intake record includes:
- Target audience
- Search intent or distribution goal
- Persona or publication voice
- Required sources or internal knowledge
- Forbidden claims
- Call to action
- Review tier
- Destination channel
For example, a creator publishing a niche blog may not need a complex editorial calendar. But they do need a repeatable brief format. Without that, every AI draft becomes a new negotiation.
A simple intake object might look like this:
content_request:
topic: human in the loop ai publishing
audience: indie creators and marketing teams
format: long-form blog post
risk_tier: medium
required_review: editor
channels:
- blog
- newsletter
claims_policy: no invented statistics
cta: invite readers to try platform
The key is not the format. The key is that the system has fields the workflow can route on.
Generation
Generation should not be treated as a single button. In production, generation is usually a sequence:
- Research collection
- Outline creation
- Draft generation
- Metadata generation
- Internal link suggestions
- Channel adaptation
- Pre-review checks
Each step can have different rules. You might allow AI to generate outlines freely, but require human approval before drafting a legal or financial advice article. You might allow automatic metadata suggestions, but require manual review for claims and examples.
The practical question is where a mistake becomes expensive. That is where you add review.
Review and release
Review is not editing. Editing is one possible action inside review.
A reviewer should be able to:
- Approve
- Reject
- Request changes
- Escalate to an expert
- Change destination channel
- Change risk tier
- Add notes for future generation
- Publish or schedule
If your review system only supports edit and publish, you do not have a loop. You have a manual checkpoint.
For a deeper workflow breakdown, the prior bl0ggers.com guide on human-in-the-loop AI publishing workflow covers review queues, routing, and quality controls from an operator angle.
Define human review as routing, not heroics
The best human reviewers are not heroic editors fixing everything manually. They are routers, validators, and decision-makers. Their job is to apply judgment where judgment is scarce.
If every draft requires deep human rewriting, the AI workflow is under-specified. If no draft requires human judgment, the workflow is over-trusted.
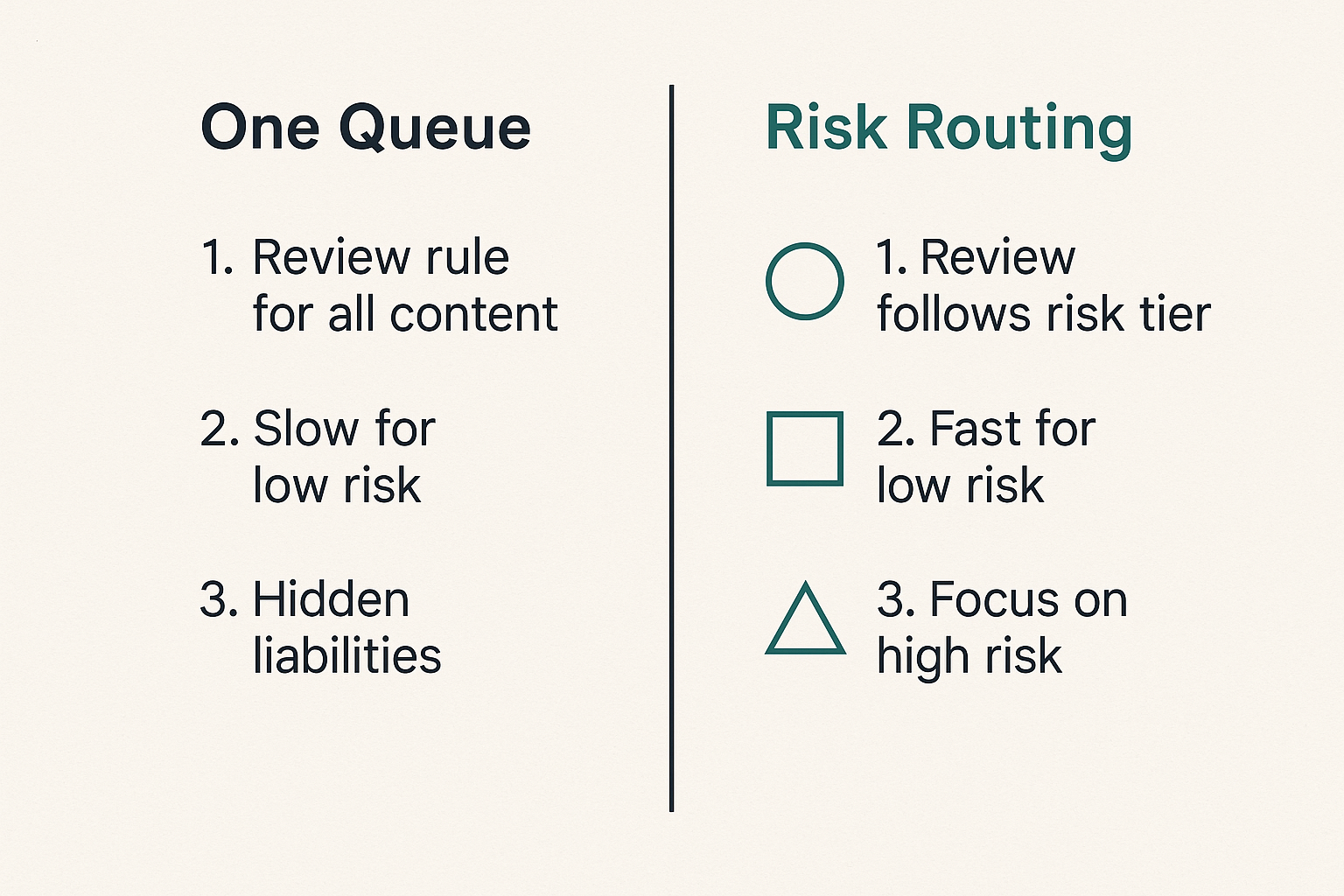
Risk tiers
Risk tiers are the simplest way to avoid review chaos. They let the workflow decide what needs attention before a human opens the draft.
| Tier | Example content | Review requirement | Automation level |
|---|---|---|---|
| Low | Evergreen glossary, simple recap, internal draft | Automated checks plus spot review | High |
| Medium | SEO article, newsletter, product comparison | Editor approval before publish | Moderate |
| High | Regulated claims, sensitive topics, brand position | Expert and editor approval | Low |
| Blocked | Unsupported medical, legal, or financial claims | Do not generate or publish | None |
The mistake teams make is building one review rule for all content. That turns low-risk work into a bottleneck and high-risk work into a hidden liability.
Practical rule: Review depth should follow content risk, not content volume.
Risk tiers also help solo creators. A solo operator can decide that personal essays and opinion pieces require full human writing, while structured roundups can use AI drafts and light review.
Ownership
Every content item needs an owner. Not a vague team. A person or role.
Ownership answers three questions:
- Who decides whether this is publishable?
- Who responds if readers flag an issue?
- Who updates the workflow so the mistake is less likely next time?
In small teams, the owner may be the creator. In marketing teams, it may be the content lead. In publisher networks, ownership may sit with a publication manager or editor for each niche site.
Without ownership, human in the loop becomes human in the blame chain.
SLAs and escalation
Review queues need service levels. Not corporate theater. Just operational expectations.
A medium-risk article might need editor review within two business days. A high-risk claim might need expert review before any scheduling. A low-risk draft might auto-expire if no one touches it after 30 days.
Escalation rules should be simple:
- If the reviewer is unsure, escalate.
- If the content makes a claim the brand cannot defend, reject or revise.
- If the content depends on current facts, verify before scheduling.
- If the same issue repeats, update the brief or template.
This prevents review from becoming personal taste. It makes review a repeatable operational layer.
Quality gates that catch problems before publication
Quality gates are checks that happen before a draft reaches the reader. Some are automated. Some require humans. The point is not to make content perfect. The point is to catch predictable failure modes early.
Brand and factual checks
AI systems can produce confident language without adequate support. That is manageable if your workflow treats claims as objects to verify, not prose to admire.
Brand and factual gates should check:
- Does the draft claim specific numbers without evidence?
- Does it imply the company offers features it does not offer?
- Does it use examples that would confuse the target reader?
- Does it contradict known positioning?
- Does it invent customer stories, citations, or case studies?
A useful workflow is to ask AI to extract claims from the draft before review. The human then reviews the claim list, not just the article body. This shortens investigation time and makes review less subjective.
SEO and usefulness checks
SEO review should not be reduced to keyword density. That is where many AI content systems go sideways.
Useful SEO checks include:
- Does the article satisfy the search intent?
- Does the opening address a real pain point?
- Are headings structured around decisions and workflows?
- Is there overlap with existing content?
- Are internal links relevant and not forced?
- Is the CTA aligned with the reader stage?
The practical question is whether the page deserves to exist. AI can make thin content longer. It cannot automatically make it necessary.
Legal and policy checks
Most creator and publisher teams do not need a giant legal department. They do need a clear policy for risky content.
Examples:
- No invented statistics
- No fake testimonials
- No professional advice framed as instruction
- No claims about competitors without verification
- No private data in prompts or outputs
- No publishing of sensitive topics without human approval
For adjacent reading from our network, security teams face a similar issue when AI-generated content intersects with detection, validation, and incident response: Related reading from our network: AI publishing threat detection as a SOC workflow.
Practical rule: If the team cannot explain how a claim was approved, the workflow is not ready to publish that claim at scale.
Workflow automation without blind autopublishing
Automation is useful when it moves known work through known states. It is dangerous when it hides uncertainty.
Human in the loop AI publishing should not mean humans manually copy drafts between tools. It should also not mean AI publishes everything because the team got tired of approvals. The right model is stateful automation.
Events and states
Every content item should move through visible states. The exact labels can vary, but the workflow should be explicit.
A practical state model:
- Idea captured
- Brief approved
- Draft generated
- Automated checks complete
- Human review pending
- Changes requested
- Approved
- Scheduled
- Published
- Monitored
This state model matters because it lets the team know where work is stuck. If 80 drafts are in human review pending, the issue is review capacity. If drafts keep returning to changes requested, the issue is intake or generation quality.
Webhooks and integrations
Publishing workflows rarely live in one tool. A content item may touch an AI system, a CMS, an email platform, analytics, and a task tracker.
Webhooks help when state changes need to trigger actions:
- Draft generated -> create review task
- Review approved -> schedule in CMS
- Article published -> send newsletter draft
- Error flagged -> reopen review item
- Performance threshold reached -> request refresh
This is where human review becomes part of the infrastructure instead of a side conversation. The reviewer decision triggers the next step.
For teams thinking about monetized publishing, payments and entitlements create similar state-management issues around access, settlement, and support: Related reading from our network: AI publishing cryptocurrency payment architecture.
Idempotency and retries
This sounds technical, but it matters for publishers. If an automation retries after a timeout, you do not want duplicate posts, duplicate newsletters, or duplicate review tasks.
Use idempotency keys for publishing actions. At minimum, every content item should have a stable ID used across systems.
Example:
publish_event:
content_id: hitlap-2026-0529-001
action: schedule_blog_post
destination: wordpress_main
idempotency_key: hitlap-2026-0529-001-schedule-blog
status: approved
What breaks in practice is not always the AI output. Sometimes it is the glue: retries, missing status updates, duplicate drafts, or unclear ownership after an integration fails.
Metrics that prove the loop is working
If you cannot measure the loop, you cannot improve it. But the metrics should reflect workflow health, not vanity volume.
Publishing 200 AI-assisted articles is not automatically better than publishing 40. The question is whether content moves faster, needs less rework, creates fewer errors, and supports the business goal.
Throughput
Throughput measures how much work moves through the system. Track it by state, not just final publication.
Useful throughput metrics:
- Ideas submitted per week
- Briefs approved per week
- Drafts generated per week
- Reviews completed per week
- Articles published per week
- Average time from brief to publish
If drafts generated rises but reviews completed stays flat, you have not scaled publishing. You have scaled backlog.
Rework
Rework is one of the clearest signals of workflow quality. If reviewers repeatedly fix the same problems, the system should change upstream.
Track:
- Percentage of drafts approved without edits
- Percentage returned for changes
- Top reasons for rejection
- Average edit time per draft
- Repeated prompt or template failures
A useful review interface should make rejection reasons structured. Free-form comments are helpful, but they are hard to aggregate. Give reviewers buttons for common issues: unsupported claim, weak angle, wrong audience, off-brand tone, duplicate topic, poor structure.
Risk reduction
Risk reduction is harder to measure, but not impossible. Track the things your workflow is designed to prevent.
Examples:
- Claims removed before publication
- Drafts escalated to expert review
- Policy violations caught pre-publish
- Reader corrections after publication
- Articles updated after monitoring
A simple dashboard might compare:
| Metric | Healthy signal | Warning signal |
|---|---|---|
| Review time | Stable or falling | Rising every week |
| Rejection reasons | Concentrated and fixable | Random and subjective |
| Escalations | Appropriate to risk tier | Everything escalates |
| Post-publish corrections | Rare and documented | Frequent and informal |
| Backlog age | Mostly current | Old drafts piling up |
The point is not to create reporting theater. The point is to know whether the loop is protecting quality while allowing scale.
What breaks when teams implement it badly
Human review can fail. Automation can fail. The combination can fail in especially annoying ways because each side assumes the other side is responsible.
The common failure modes are predictable.
The queue becomes a graveyard
A review queue without priority is just a backlog with a nicer name.
This happens when every draft lands in the same place, no one owns triage, and there is no expiration policy. Drafts sit for weeks. By the time someone reviews them, the topic is stale or the campaign has moved on.
What works:
- Prioritize by campaign, risk, and freshness
- Auto-archive stale low-priority drafts
- Show queue age by owner
- Limit work in progress
What fails:
- One generic review queue
- No SLA
- No owner
- No way to reject quickly
Reviewers edit everything
Some teams turn human review into full manual rewriting. That feels safe, but it destroys leverage.
If reviewers edit everything, ask why. Usually one of three things is wrong:
- The brief is too vague.
- The generation template is too generic.
- The reviewer has no clear approval criteria.
The fix is not to tell reviewers to move faster. The fix is to improve the upstream system and define what review means.
A reviewer should not be responsible for rescuing bad prompts all day.
Automation hides accountability
The most dangerous implementation is the one where nobody knows why something was published.
Bad signs:
- Drafts publish without approval logs
- AI-generated changes overwrite human edits
- No one can see which prompt or source produced a claim
- Failed webhook retries create duplicate content
- Corrections happen in private chats and never update the workflow
Practical rule: Every published AI-assisted asset should have an audit trail: source brief, generation step, reviewer, approval decision, and publication destination.
This does not need to be heavy. Even a small team can log these fields in a CMS, spreadsheet, or publishing platform. The point is traceability.
What works in production
Good human in the loop AI publishing systems are usually less glamorous than demos. They rely on narrow scopes, clear templates, structured review, and boring operational discipline.
That is good news. You do not need a massive AI transformation program. You need a workflow that can survive real publishing pressure.
Start with narrow lanes
Do not automate the entire content operation on day one. Pick lanes where the risk is understood and the format is repeatable.
Good starting lanes:
- Evergreen educational articles
- Podcast transcript summaries
- Newsletter drafts from approved posts
- Product update recaps
- Local or niche topic roundups
- Internal knowledge base drafts
Avoid starting with high-stakes thought leadership, sensitive claims, or topics where your brand point of view is still unclear.
The narrower the lane, the easier it is to define quality.
Use templates
Templates are not creative handcuffs. They are operational memory.
A good content template captures:
- Intended reader
- Opening pain point
- Required argument structure
- Examples to include
- Examples to avoid
- Internal links to consider
- CTA rules
- Review checklist
Templates also help reviewers. Instead of asking whether a draft is good in the abstract, the reviewer asks whether it satisfies the template and whether the template is still correct.
Close the feedback loop
A loop is not a loop unless feedback changes the system.
When a reviewer rejects a draft, that decision should inform future generation. When readers flag an issue, that should update policy or prompts. When analytics show a format works, that should influence briefs.
The operating model matters here. The prior bl0ggers.com article on human-in-the-loop AI publishing operating model goes deeper on ownership, QA, and governance for teams scaling beyond ad hoc AI usage.
A simple feedback workflow:
- Reviewer selects a structured issue.
- Editor adds optional notes.
- Workflow stores the issue against template and topic.
- Prompt or brief template is updated.
- Future drafts are compared against the same issue.
- Metrics show whether the issue declines.
That is the loop. Without it, human review is just manual labor attached to AI output.
Team operating model for creators and publishers
Different teams need different levels of process. The architecture should match the risk and volume of the publishing operation.
Solo creator
A solo creator usually needs speed, consistency, and protection from publishing weak drafts too quickly.
Recommended model:
- AI helps with research, outlines, repurposing, and first drafts
- Creator approves angles before generation
- Creator reviews final drafts before publishing
- Low-risk repurposed content can be scheduled with light review
- A simple checklist catches claims, tone, and CTA fit
The creator should protect the parts that make the work distinct: opinion, judgment, taste, lived experience, and relationship with the audience.
Marketing team
A marketing team needs coordination. Multiple people touch the workflow: demand generation, SEO, product marketing, subject matter experts, and design.
Recommended model:
- Content lead owns the queue
- SEO or campaign owner approves briefs
- AI generates drafts and variations
- SMEs review technical or product claims
- Editor approves final publish
- Performance data triggers refresh tasks
The mistake marketing teams make is letting AI create more work for SMEs. SMEs should review claim lists and key sections, not line-edit entire drafts unless the content is high risk.
Publisher network
A publisher network needs repeatability across many sites, personas, or channels.
Recommended model:
- Standardized intake across publications
- Publication-specific voice templates
- Central policy rules
- Local editor or owner per property
- Shared analytics and issue taxonomy
- Automated routing by topic, risk, and destination
At this level, human in the loop AI publishing becomes infrastructure. The system must support many small decisions without requiring one central editor to approve everything.
Where bl0ggers.com fits
Human in the loop AI publishing is a good fit for teams that want AI speed without giving up editorial control. The product question is not whether a tool can generate words. Many can. The better question is whether the tool supports the workflow around those words.
A practical fit
bl0ggers.com is built around the reality that creators and publishers use AI to scale content production while maintaining human oversight. That means the useful parts are not just generation. They are review queues, persona-led publishing, generated article workflows, podcast and newsletter adaptation, and subdomain media operations.
If you are evaluating platform fit, look for whether the system can support:
- Human approval before publication
- Different workflows for different content types
- Persona and publication context
- Multi-channel output
- Clear content states
- Integrations with downstream publishing systems
You can learn more about the platform direction on the bl0ggers.com about page, especially if you are thinking in terms of persona-led blogs, podcasts, newsletters, and subdomain publishing.
Integration points
The strongest implementation pattern is to treat the platform as part of a publishing stack, not as an isolated writing tool.
Useful integration points include:
- Topic intake from a planning system
- Draft generation from approved briefs
- Human review before release
- Webhooks into CMS or newsletter tools
- Status updates back into the editorial queue
- Analytics-driven refresh tasks
The goal is controlled throughput. AI handles repeatable production work. Humans handle judgment, approval, correction, and strategy.
Human in the loop AI publishing is the architecture that keeps those responsibilities separate.
Try bl0ggers.com
bl0ggers.com is for creators and publishers who use AI to scale content production while maintaining human oversight. If you want a workflow built around AI-assisted blogs, newsletters, podcasts, review queues, and publishing automation, Try bl0ggers.com.