
AI can generate more content than your team can comfortably review. That sounds like a productivity win until drafts pile up, editors become bottlenecks, and nobody can explain why one article shipped while another stayed in limbo.
Teams think the problem is content generation. The real problem is publishing control.
Human in the loop AI publishing is not about occasionally asking a person to read an AI draft. It is about designing a workflow where machines handle repeatable production steps and humans own judgment, risk, positioning, and release decisions. That changes the conversation.
The practical question is not, “Can AI write this?” It is, “Where should human review sit in the publishing system so we can scale output without scaling mistakes?”
Table of contents
- Human in the loop AI publishing is an operating model
- Design the publishing pipeline before adding more AI
- Put humans at the highest-leverage checkpoints
- Build a review queue that operators can actually use
- Control quality with rules, not vibes
- Automation should move work, not hide work
- What breaks when AI publishing is implemented badly
- A practical implementation workflow for 2026
- Human review patterns by team size
- Where bl0ggers.com fits in the workflow
Human in the loop AI publishing is an operating model

Human in the loop AI publishing means people remain part of the decision path for content that affects brand, trust, revenue, or audience relationships. The AI may research, outline, draft, reformat, repurpose, summarize, and schedule. The human decides whether the work is accurate, aligned, useful, and ready.
The mistake teams make is treating the human as a final spellcheck layer. By the time an editor sees a weak AI-generated article, the system has already wasted compute, attention, calendar space, and sometimes a publishing slot.
A useful way to think about it is pipeline design. You are not buying a magic writer. You are designing an editorial production line where different actors have different permissions.
Why the review step cannot be an afterthought
If review is informal, the workflow depends on memory. Someone checks a claim because they happened to notice it. Someone changes the headline because it felt off. Someone blocks publication because the article mentions a competitor incorrectly.
That does not scale.
Human review needs a defined place in the workflow, a clear purpose, and a consequence. A review step that cannot approve, reject, request revision, or route work elsewhere is not control. It is theater.
Practical rule: If a human review step does not change what happens next, remove it or redesign it.
For publishers, the review step should answer specific questions:
- Is the topic worth publishing for this audience?
- Does the draft match the intended angle?
- Are factual claims safe enough for the risk level?
- Does the piece connect to the publication’s existing strategy?
- Is the asset ready for distribution, syndication, or repurposing?
The difference between assistance and autonomy
AI assistance improves an existing human workflow. AI autonomy executes a workflow without waiting for human judgment. Both can be useful, but they should not be confused.
For example, an AI assistant can generate five headline options for an editor. An autonomous publishing system can select one, publish it, email it, post it to social, and trigger a webhook to another tool. Those are different risk profiles.
The practical question is where autonomy is safe. Formatting a transcript into a draft is usually low risk. Publishing medical, legal, financial, or reputational claims without review is not.
What humans should actually control
Humans should control the parts of publishing where context matters more than speed:
- Editorial strategy
- Brand positioning
- Sensitive claims
- Audience promises
- Source trust
- Final publication authority
- Pattern correction after performance data arrives
The AI should control repeatable tasks that are expensive for humans but easy to check: summarization, first drafts, metadata suggestions, internal linking candidates, newsletter snippets, podcast show notes, and variant generation.
The operating model works when every task has a default owner: AI, human, or system automation.
Design the publishing pipeline before adding more AI
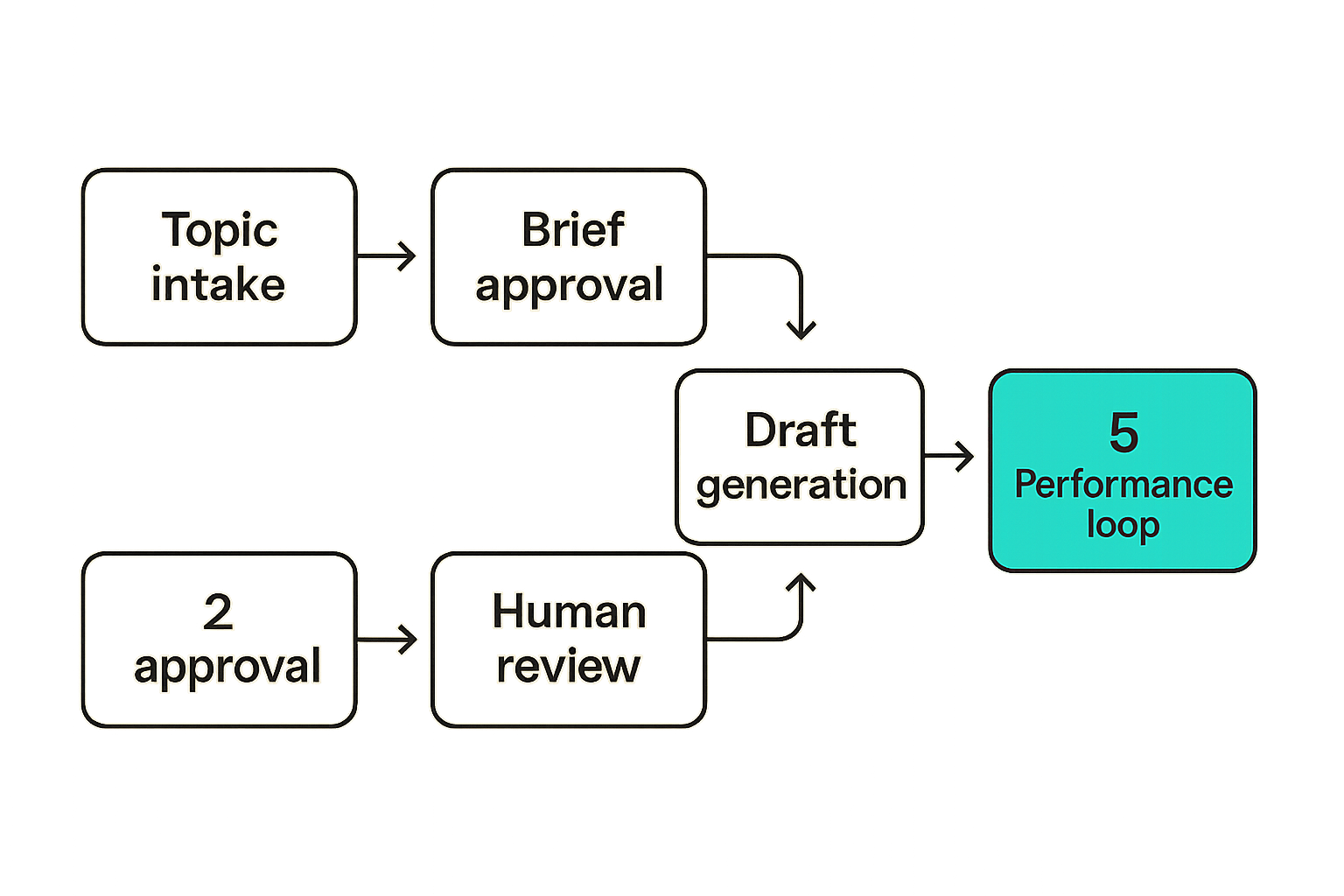
Most content teams add AI at the draft stage because that is where the output is visible. But the draft is only one object in the system. Before the draft, there is topic selection, keyword intent, audience fit, brief approval, source gathering, and angle definition. After the draft, there is editing, compliance, formatting, publishing, distribution, measurement, and refresh.
If you automate only writing, you create faster chaos.
Map the lifecycle from idea to distribution
A practical human in the loop AI publishing pipeline usually looks like this:
- Topic intake — ideas come from search demand, audience questions, product launches, sales calls, community threads, or creator intuition.
- Brief generation — AI turns inputs into an outline, audience promise, angle, and required sections.
- Human brief review — an editor approves the direction before a full draft is generated.
- Draft production — AI creates the article, newsletter, podcast outline, or repurposed asset.
- Quality checks — the system flags missing sections, unsupported claims, duplicate angles, weak titles, or off-brand language.
- Human editorial review — a person approves, requests revision, or rejects.
- Publishing and distribution — approved assets move to CMS, newsletter, podcast, social, or subdomain publishing workflows.
- Performance review — humans decide what to repeat, update, merge, or stop producing.
This sequence matters because humans review the plan before the expensive part happens. It is easier to fix a bad brief than a bad 2,000-word article.
Related reading from our network: teams thinking about answer engine visibility should also look at AI publishing schema markup, because structured content becomes easier to validate when it is planned before publication.
Separate generation from approval
Generation should create candidates. Approval should release assets.
When those two steps blur, teams publish drafts because they exist, not because they are ready. This is especially dangerous when volume becomes the goal. AI makes it cheap to create more inventory, but every published page still carries brand risk.
Use separate permissions:
| Workflow function | AI can do | Human should do | System should enforce |
|---|---|---|---|
| Topic suggestion | Generate ideas | Choose strategic fit | Prevent duplicates |
| Brief creation | Draft outline | Approve angle | Require required fields |
| Article drafting | Produce draft | Judge usefulness | Track version history |
| Fact handling | Flag claims | Verify sensitive claims | Store sources and notes |
| Publishing | Prepare asset | Approve release | Block unapproved status |
| Repurposing | Create variants | Approve messaging | Preserve canonical source |
This table is simple, but it prevents a common failure: letting the tool’s output become the team’s decision.
Make status visible to everyone
What breaks in practice is not always quality. Often it is status.
Nobody knows whether a draft is waiting on legal review, editor review, source verification, image selection, or scheduling. AI then generates more drafts into the same clogged pipe.
Use explicit states:
- Idea submitted
- Brief generated
- Brief approved
- Draft generated
- Needs source review
- Needs editorial review
- Revision requested
- Approved for publish
- Published
- Needs refresh
- Archived
Status visibility is what lets teams scale without meetings. It also makes human oversight measurable instead of anecdotal.
Put humans at the highest-leverage checkpoints
The goal is not to put a human everywhere. That defeats the point of automation. The goal is to put people where one decision prevents many downstream errors.
A human in the loop AI publishing system should use checkpoints, not constant interruption.
Review briefs before drafts
Brief review is the most underrated control point. A brief captures the target reader, angle, search intent, examples, claims to avoid, sources to use, and desired conversion path.
If the brief is wrong, the draft will probably be wrong. If the brief is strong, the AI has a much better chance of producing something useful on the first pass.
Brief review should be fast. The editor is not rewriting the article. They are checking direction:
- Is this topic aligned with our audience?
- Is the angle specific enough?
- Is the article differentiated from what we already published?
- Are there claims that need careful handling?
- Does the CTA match the reader’s stage?
Practical rule: Review direction early and language late. Do not spend human time polishing a draft built on a weak premise.
Review claims before publication
Not every sentence needs the same scrutiny. A personal productivity tip is not the same as a financial recommendation. A general industry observation is not the same as a technical implementation claim.
Create factual risk tiers:
| Risk tier | Example content | Human review requirement |
|---|---|---|
| Low | Opinion, workflow tips, general advice | Editorial review |
| Medium | Tool comparisons, technical how-to, market positioning | Editorial plus source check |
| High | Legal, medical, financial, security, compliance claims | Subject-matter review required |
This is where human in the loop stops being a slogan. The workflow must know when an editor is enough and when a specialist is required.
Review performance before repeating patterns
AI systems are good at repeating patterns. That is useful only if the patterns are worth repeating.
Every month or publishing cycle, a human should look at what the AI helped produce and ask:
- Which topics earned attention from the right audience?
- Which formats created review drag?
- Which drafts required heavy rewriting?
- Which prompts produced generic output?
- Which content should be refreshed, consolidated, or killed?
Without this loop, teams automate yesterday’s assumptions. The content calendar fills up, but strategy does not improve.
Build a review queue that operators can actually use

The review queue is the operational center of human in the loop AI publishing. It is where generated work becomes accountable work.
A bad review queue is just a pile of drafts. A good review queue shows priority, risk, owner, status, due date, source notes, and the exact action needed from the human.
Use clear states and owners
Every item in the queue should have one owner and one next action. Shared ownership sounds collaborative, but it often means nobody is responsible.
Useful queue fields include:
- Content type
- Target persona
- Topic or keyword
- Current state
- Assigned reviewer
- Risk tier
- Source status
- Due date
- Publication destination
- Last change
- Required action
The required action matters. “Review this” is vague. “Approve brief,” “verify claims,” “choose CTA,” and “approve for publish” are operationally useful.
Set thresholds for automatic routing
Not all content should go to the same reviewer. Automatic routing saves time when it is based on sensible thresholds.
Examples:
- High-risk claims route to a subject-matter expert.
- Product comparison articles route to marketing leadership.
- Technical implementation guides route to the person who owns the workflow.
- Low-risk newsletter summaries route to a standard editorial queue.
- Content over a certain length receives structural QA before human review.
This is also where automation can protect humans from noise. The system should not ask a senior editor to review every metadata suggestion. It should escalate only when the decision matters.
Related reading from our network: security teams face a similar workflow problem in SaaS incident response architecture, where signals, ownership, routing, and escalation determine whether automation helps or creates noise.
Avoid the infinite edit loop
The infinite edit loop happens when reviewers keep improving content without a defined acceptance bar. This is expensive and demoralizing.
Set exit criteria:
- The article satisfies the brief.
- Claims meet the required risk standard.
- Structure is clear.
- Voice is within acceptable range.
- CTA and internal links are correct.
- No blocker issues remain.
Then ship it, schedule it, or reject it. Do not let every AI-assisted article become a philosophical debate about what “good” means.
Practical rule: A review queue should reduce ambiguity. If it increases debate, the acceptance criteria are too vague.
Control quality with rules, not vibes
Quality control in AI publishing fails when teams rely on taste alone. Taste matters, but taste is hard to automate, delegate, or audit.
Rules are not a replacement for editorial judgment. They are a way to make judgment repeatable.
Codify voice and positioning
A useful voice guide for AI-assisted publishing should be operational, not poetic. “Be smart and engaging” is not useful. “Use direct explanations, avoid hype, include implementation tradeoffs, and define terms only when needed” is useful.
Codify:
- Audience sophistication
- Allowed and banned phrases
- Preferred article structure
- Claims the brand will not make
- Competitors or categories to handle carefully
- CTA patterns by content type
- Examples of acceptable and unacceptable output
The goal is not to freeze creativity. The goal is to give the system and reviewers the same target.
Use factual risk tiers
Factual QA should be proportional to risk. Many teams either over-check everything or under-check dangerous claims. Both fail.
A practical process:
- Identify claims that could be wrong in a meaningful way.
- Classify claims by risk tier.
- Require sources or reviewer notes for medium and high risk claims.
- Block publication if required claim fields are empty.
- Store verification notes with the content record.
For example, “AI can help repurpose a podcast transcript” is low risk. “This workflow guarantees search rankings” is a claim you should avoid. “This legal compliance process is sufficient” may require expert review or should not be published at all.
Validate structure before style
Editors often start with wording because wording is visible. But structural problems cause more rework.
Check these first:
- Does the article answer the reader’s real question?
- Are sections in a logical order?
- Is the intro specific to the problem?
- Are examples concrete enough?
- Are claims supported or framed carefully?
- Is the CTA relevant to the reader’s stage?
Only after structure passes should reviewers spend time on phrasing. Otherwise, they polish paragraphs that may be deleted.
Automation should move work, not hide work
Automation is valuable when it moves the right work to the right place at the right time. It is dangerous when it makes important steps invisible.
The mistake teams make is wiring tools together and assuming the workflow is solved. A draft moving automatically from an AI tool into a CMS is not a publishing system. It is a transport mechanism.
Trigger generation from approved inputs
Do not let every raw idea trigger a full article. Trigger generation from approved briefs or structured inputs.
Minimum approved input fields might include:
- Target reader
- Search intent or audience need
- Content format
- Angle
- Required sections
- Claims to avoid
- Source requirements
- CTA or conversion path
- Distribution destination
This keeps the AI from filling gaps with generic assumptions. It also gives reviewers a stable object to approve before generation begins.
Use webhooks and notifications carefully
Notifications should call for action, not announce noise. If every generated draft pings Slack, people stop paying attention.
Use event-based triggers:
- Brief ready for approval
- Draft failed automated QA
- High-risk claim detected
- Reviewer requested changes
- Article approved for publication
- Scheduled content failed to publish
- Published article needs refresh
The same principle applies to webhooks. Send clean events with useful state, not vague payloads that downstream tools need to interpret from scratch.
Keep an audit trail
Human oversight requires memory. An audit trail answers who approved what, when, and why.
Track:
- Prompt version or generation configuration
- Source inputs
- AI-generated versions
- Human edits
- Reviewer comments
- Approval events
- Publishing destination
- Refresh history
This is not bureaucracy for its own sake. It protects the team when something is questioned later and helps improve the system over time.
What breaks when AI publishing is implemented badly
Bad AI publishing systems do not always fail immediately. They often appear productive for a few weeks because output rises. Then the hidden costs show up.
The practical question is not whether the tool can generate content. It is whether the operating model can absorb, review, improve, and responsibly publish that content.
Editors become cleanup crews
If AI drafts arrive without approved briefs, source expectations, or quality gates, editors become cleanup crews. They spend their time untangling vague arguments, correcting overconfident claims, and rewriting generic sections.
This creates a predictable backlash: the team concludes AI is not useful. But the real failure was upstream design.
What fails:
- Generating drafts from thin prompts
- Asking editors to fix strategy at the sentence level
- Measuring output volume but not review effort
- Treating rewrites as normal instead of diagnostic
What works:
- Reviewing briefs before drafts
- Routing high-risk work separately
- Capturing recurring edit reasons
- Updating prompts, templates, and rules based on review patterns
Content libraries drift off strategy
AI makes it easy to produce adjacent content. Adjacent content can be useful, but it can also dilute a publication.
A marketing team focused on AI publishing might suddenly have dozens of articles about general productivity, generic creator tips, or broad technology trends. Each article looks acceptable alone. Together, the library loses focus.
Prevent drift with portfolio-level review:
- Define core topic clusters.
- Set limits on experimental categories.
- Track which personas each article serves.
- Review overlap before approving new briefs.
- Consolidate or retire weak content.
Related reading from our network: community operators face similar routing and trust problems when choosing the best platform for local community building, because the tool matters less than the operating workflow around it.
Support and reputation costs show up late
Publishing errors have delayed costs. A misleading article may create confused leads, support tickets, social criticism, or internal distrust. A vague tutorial may waste readers’ time. A poorly reviewed comparison may damage partner relationships.
These costs rarely appear in the content dashboard. They show up in sales calls, customer support, comments, unsubscribes, and brand perception.
That is why human oversight should be designed before the first large batch of AI content goes live.
A practical implementation workflow for 2026
Human in the loop AI publishing in 2026 should be built in stages. Do not start by automating every channel. Start with one repeatable lane, make it reliable, then expand.
Start with one content lane
Choose a lane with clear value and manageable risk. Examples:
- Weekly blog posts from approved briefs
- Podcast transcripts turned into show notes and newsletters
- Product update summaries
- SEO support articles
- Creator essays repurposed into newsletters
- Interview transcripts turned into draft articles
Avoid starting with your highest-risk content. Prove the workflow where mistakes are recoverable.
Define acceptance criteria
Before the first AI draft, define what “ready” means.
An acceptance checklist might include:
- Approved brief exists.
- Target reader is clear.
- Article matches the intended angle.
- No unsupported high-risk claims remain.
- Sources are included where required.
- Structure matches the template.
- Internal links and CTA are correct.
- Human reviewer approved publication.
This checklist becomes the basis for automation, QA, and review training.
Measure review load, not just output
Output volume is easy to measure. Review load is more important.
Track:
- Drafts generated
- Drafts approved
- Drafts rejected
- Average review time
- Common revision reasons
- Percentage requiring major rewrite
- Time from brief approval to publication
- Performance by content lane
If AI doubles output but triples review load, the system is not working. If AI increases output while keeping review time manageable and quality stable, the model is improving.
Human review patterns by team size
The right human in the loop design depends on team size. A solo creator does not need the same workflow as a digital publisher with multiple brands, channels, and reviewers.
The principles are the same, but the operating model changes.
Indie creators
For indie creators, the human is often the strategist, editor, and publisher. The risk is not bureaucracy; it is context switching.
A lightweight workflow works best:
- Capture raw ideas quickly.
- Let AI create briefs and first drafts.
- Review the brief before generating long-form content.
- Use a simple checklist before publishing.
- Repurpose approved work into newsletters, threads, and podcast notes.
The creator should spend most of their time on perspective, examples, stories, and final approval. AI should handle formatting and expansion.
Small marketing teams
Small teams need role clarity. The founder, marketer, editor, and subject expert may all touch the content, but not every person should review every asset.
A workable pattern:
- Marketing owns the calendar and briefs.
- Subject experts review technical or product claims.
- Editors review structure, voice, and usefulness.
- Automation moves approved assets into publishing and distribution.
This prevents the common “everyone has comments” problem. Review becomes staged, not chaotic.
Digital publishers
Publishers need throughput, governance, and portfolio control. They may operate multiple personas, newsletters, subdomains, or topic clusters.
For them, human in the loop AI publishing should include:
- Persona-specific templates
- Reviewer assignment rules
- Risk-based routing
- Publishing permissions
- Version history
- Performance review by cluster
- Refresh workflows
- Clear escalation paths
At this scale, the system matters as much as the model. The winners are not the teams with the most prompts. They are the teams with the cleanest operating loops.
Where bl0ggers.com fits in the workflow
A human in the loop AI publishing platform should not just generate text. It should help creators and publishers run the workflow around generation: personas, review queues, approvals, publishing destinations, and repeatable automation.
That is the problem space bl0ggers.com describes as human-in-the-loop AI publishing: AI-assisted production with human oversight for creators, publishers, podcasts, newsletters, and subdomain media networks.
Persona-led publishing instead of generic generation
Generic AI content usually comes from generic inputs. Persona-led publishing starts with who the content is for and what role the content plays.
A persona-led workflow can define:
- Reader segment
- Content promise
- Tone and depth
- Recurring objections
- Preferred examples
- CTA path
- Distribution channel
This gives AI better constraints and gives human reviewers a clearer target. The point is not to make every article sound identical. The point is to prevent the system from drifting into bland, interchangeable content.
If you are mapping generated articles into blogs, podcasts, newsletters, or subdomain publishing workflows, it can be useful to contact bl0ggers.com about the operational pieces: review queues, integrations, persona journeys, and automation boundaries.
Review queues for controlled scale
Controlled scale is the core requirement. More output is only useful if the team can review, approve, publish, and learn from it.
In practice, that means:
- AI creates structured drafts from approved inputs.
- Humans review the decisions that matter.
- Automation routes assets without hiding responsibility.
- Publishing destinations receive only approved work.
- Performance data feeds the next planning cycle.
This is the architecture behind human in the loop AI publishing. The UI matters, but the workflow matters more.
Try bl0ggers.com
bl0ggers.com is for creators and publishers who use AI to scale content production while maintaining human oversight. If you want AI-assisted blogs, newsletters, podcasts, review queues, and publishing automation without giving up editorial control, Try bl0ggers.com.
Human in the loop AI publishing is not a compromise between speed and quality. It is the operating model that lets teams decide where speed is safe and where human judgment still belongs.