
A content automation workflow usually starts as a capacity problem. The team needs more articles, newsletters, social posts, podcast summaries, landing page variants, or partner updates than the current calendar can absorb.
So someone adds AI. Then another tool. Then a scheduler. Then a review spreadsheet. For a few weeks, output goes up. Then the real failure shows up: nobody knows which draft is approved, what changed, who owns the final call, whether the article matches the brief, or why performance is drifting.
Teams think the problem is content volume. The real problem is workflow state.
That changes the conversation. A useful content automation workflow is not a pile of prompts. It is an operating system for moving ideas from research to approved publishing assets with the right checkpoints, owners, and feedback loops. In 2026, the practical question is not whether AI can generate content. It can. The practical question is whether your publishing system can absorb that output without creating editorial debt.
Table of contents
- Content automation workflow is an operating system, not a prompt stack
- Map the publishing state machine before you automate
- Build review lanes instead of one generic approval step
- Quality gates that catch problems before publication
- Design inputs so AI produces usable drafts
- Automate distribution without losing channel context
- Measurement closes the workflow loop
- What breaks when content automation is implemented badly
- Implementation sequence for 2026 content teams
- Where bl0ggers.com fits in the workflow
- Closing checklist for a durable content automation workflow
Content automation workflow is an operating system, not a prompt stack
The mistake teams make is treating content automation as a generation problem. They ask which model writes the best draft, which prompt template produces the cleanest intro, or which tool can publish directly to the CMS.
Those questions matter, but they are not the architecture. The architecture is the chain of decisions around the draft: why it exists, what it is allowed to say, who checks it, which channels receive it, what happens if it underperforms, and how the learning returns to the next brief.
A content automation workflow should answer five operational questions:
- What input triggers a content asset?
- What state is the asset in right now?
- What checks must pass before it moves forward?
- Who can approve, reject, revise, or publish it?
- What performance data changes future production?
Related reading from our network: SaaS teams face the same automation trap when tools are connected before workflow ownership is defined, which is why this piece on automation direct in SaaS workflow architecture is a useful adjacent comparison.
The workflow owns state
State is the difference between automation and chaos. A draft is not just a document. It is an object moving through a system.
Useful states are boring and explicit:
- idea captured
- brief approved
- research attached
- draft generated
- editorial review
- subject matter review
- legal or compliance review, if needed
- scheduled
- published
- refreshed
- archived
Without state, the team relies on Slack memory and spreadsheet color codes. That works until volume increases. Then drafts get published twice, stale claims survive revisions, and nobody can explain why an article skipped review.
Practical rule: If you cannot describe the current state of a content asset in one sentence, you are not ready to automate its next step.
The editor owns risk
AI can create drafts, summaries, outlines, metadata, and channel variants. It should not silently decide business risk.
Risk belongs to humans with context. An editor might approve a low-risk SEO glossary post after a quick pass. A founder quote, medical claim, financial recommendation, security assertion, or competitor comparison needs a deeper lane. The same generation system can serve both, but the workflow cannot treat both assets the same.
The practical question is not whether humans review everything. The practical question is where human attention creates the most value.
Map the publishing state machine before you automate
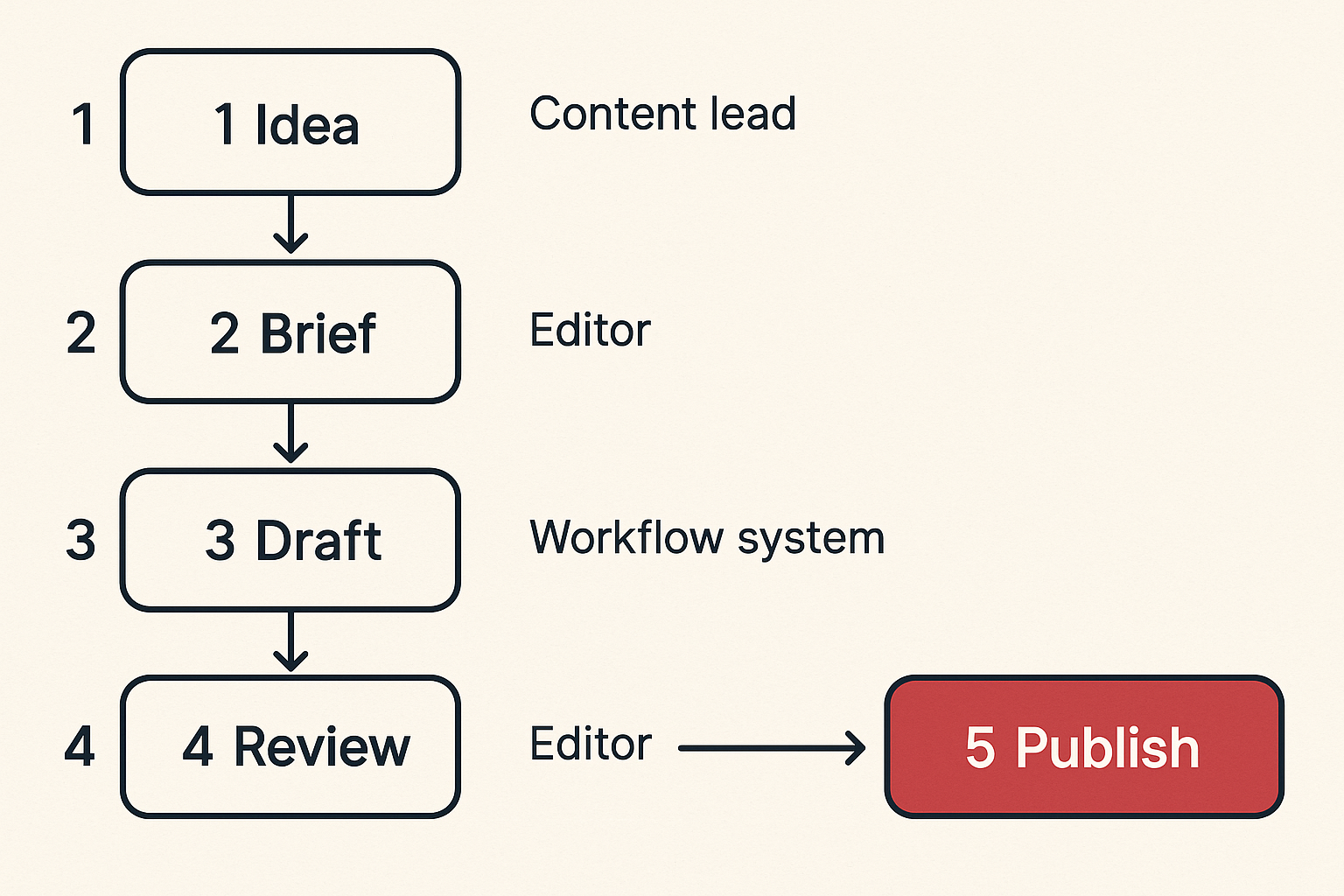
A publishing state machine sounds heavier than most content teams want. In practice, it is just a shared map of what can happen to an asset and what cannot.
If the team does not define the state machine, the automation tool will do it implicitly. That is usually where problems start. Drafts skip the wrong review, content goes live with placeholder links, or an approved article gets overwritten by a regenerated version.
States every team should define
Start with fewer states than you think you need. Too many states create process theater. Too few create ambiguity.
A practical baseline looks like this:
| State | Meaning | Required owner | Exit condition |
|---|---|---|---|
| Idea captured | Topic exists but has no approved angle | Content lead | Accepted or rejected |
| Brief approved | Intent, audience, sources, and CTA are clear | Editor | Draft generation can begin |
| Draft generated | AI or writer created a first version | Workflow system | Automated checks complete |
| Editorial review | Human checks structure, voice, claims, and fit | Editor | Approved, revised, or rejected |
| Channel packaging | Asset is adapted for newsletter, social, CMS, or podcast | Producer | Channel assets ready |
| Scheduled | Publication time and destination are set | Publisher | Publish job succeeds or is paused |
| Published | Asset is live | System | Performance tracking begins |
| Refresh queued | Asset needs update, expansion, or pruning | Content lead | New brief or archive decision |
This table is not meant to be perfect. It is meant to expose decisions. Once the states are visible, automation becomes safer because every trigger has a defined destination.
Transitions need owners
The transition is where mistakes hide. Moving from draft generated to editorial review sounds obvious. But what happens if the draft fails originality checks? What if the source set is incomplete? What if the article was generated against an old persona?
Each transition needs three things:
- a trigger, such as draft created or editor approved
- a guardrail, such as source count, word range, or risk level
- an owner, either a person, role, or system
A simple transition rule can look like this:
transition: draft_generated_to_editorial_review
trigger: generation_complete
guards:
- source_policy_passed
- required_sections_present
- no_placeholder_text
owner: managing_editor
fallback: send_to_revision_queue
The exact syntax does not matter. The discipline does. What breaks in practice is not that teams lack tools. It is that transitions rely on assumptions.
Build review lanes instead of one generic approval step
Most teams start with one approval step. Everything goes to the editor. That feels safe. It also becomes the bottleneck.
A better content automation workflow uses review lanes. The lane is based on risk, content type, audience impact, and business importance. This is where human-in-the-loop publishing becomes operational instead of symbolic. For a deeper architecture view, the prior bl0ggers.com guide to human-in-the-loop AI publishing workflow architecture maps review routing, quality gates, and ownership in more detail.
Fast lane for low risk content
Fast lane content is useful, repeatable, and low downside. Examples include:
- event recaps
- product changelog summaries
- internal knowledge base drafts
- basic SEO support articles
- newsletter roundup blurbs
- social variants from an approved article
The fast lane still needs gates. It just does not need a committee. The editor should be able to review structure, remove weak claims, confirm the CTA, and approve quickly.
Fast lane rules usually include:
- approved source set only
- no new legal, medical, financial, or security claims
- no named competitor comparisons unless pre-approved
- no new brand positioning
- limited publication destinations
Deep lane for strategic content
Deep lane content needs more review because the downside is higher. Examples include:
- thought leadership from executives
- original research summaries
- conversion pages
- partner announcements
- regulated industry content
- sensitive opinion pieces
- high-traffic evergreen pages
The deep lane should not be a vague more review bucket. Define the extra steps. Who checks the claims? Who approves the point of view? Who confirms that the CTA matches the campaign? Who signs off before scheduling?
| Review model | What works | What fails |
|---|---|---|
| One approval step | Simple at low volume | Becomes a queue where every asset waits for the same person |
| Review lanes | Matches effort to risk | Requires clear routing rules |
| Full manual review | Useful for sensitive content | Kills throughput if applied to everything |
| Fully automated publishing | Fast for controlled formats | Dangerous when claims, context, or brand judgment matter |
Practical rule: Do not automate around your editor. Automate the low-value work around the editor so human review is spent on judgment, not copy-paste operations.
Quality gates that catch problems before publication
Quality gates are not the same as proofreading. A proofread catches grammar and awkward wording. A gate decides whether the asset is allowed to move forward.
The mistake teams make is putting every quality concern into the final review step. By then, the article has already consumed generation time, editing time, and scheduling attention. Better gates move cheap checks earlier.
Related reading from our network: privacy-heavy teams use similar gating logic for message handling and governance, and the workflow patterns in VA secure messaging privacy architecture translate well to editorial approval systems where leakage and ownership matter.
Gate checks that should be automated
Automated gates are good for deterministic checks. They should not pretend to understand strategy. They should catch obvious problems before a human spends time.
Good automated checks include:
- required sections present
- title and meta description length within range
- internal link count meets policy
- external links are allowed domains
- no placeholder text remains
- no forbidden phrases or off-brand claims
- reading level within acceptable range
- duplicate title or slug detection
- image placeholders present or absent based on template
- schema fields complete
- publish destination selected
These checks do not need to be glamorous. They need to be consistent.
Gate checks that need human judgment
Human gates are for context, taste, and risk. A model can suggest. It cannot be accountable for positioning.
Human checks include:
- Does the article say something specific enough to be worth publishing?
- Is the angle aligned with the audience and funnel stage?
- Are the claims defensible from the supplied sources?
- Does the voice sound like the publication, not like the average internet?
- Is the CTA useful in context?
- Would this piece still make sense if read by a customer, partner, or competitor?
A useful gate produces a decision, not just comments. Approve, revise, reject, or escalate. Anything else creates drift.
Practical rule: Automate checks that can be evaluated the same way every time. Keep humans on checks where context changes the answer.
Design inputs so AI produces usable drafts
AI output quality is usually blamed on the model. Sometimes that is fair. More often, the input system is weak.
If the brief is vague, the draft will be vague. If the source policy is unclear, the draft will borrow generic assumptions. If the audience is defined as marketers instead of newsletter operators managing three approval paths and a weekly sponsor deadline, the output will flatten.
Briefs beat prompts
A prompt is an instruction. A brief is an operating context.
A practical brief should include:
- target reader
- current pain point
- search intent or reader intent
- business purpose
- allowed sources
- forbidden claims
- required examples
- desired CTA
- tone constraints
- distribution targets
- review lane
Here is a compact brief structure that works well in production:
topic: content automation workflow
reader: newsletter operator scaling weekly publishing
intent: practical architecture and implementation
risk_level: medium
required_sections:
- state machine
- review lanes
- quality gates
- distribution
- measurement
source_policy: supplied sources plus approved internal knowledge
cta: try human-in-the-loop publishing workflow
review_lane: editorial plus operator review
The brief becomes the contract between strategy, generation, review, and measurement.
Source policy prevents cleanup debt
Source policy is where many teams get casual. They ask AI to write about a topic, then rely on editors to catch weak claims. That is backwards.
Define what the system can use:
- first-party product docs
- approved interviews
- customer research notes
- existing articles
- public documentation
- analyst or industry sources, if supplied
- no unsourced statistics
- no invented customer examples
When sources are not available, the workflow should force a different output type. Write a practical opinion piece, a checklist, or a workflow guide. Do not let the system manufacture authority.
Automate distribution without losing channel context

Publishing is not finished when the article is approved. For many content teams, that is when the operational mess begins.
The article needs a CMS version, newsletter version, social version, maybe a podcast outline, maybe a short-form video script, maybe a partner syndication summary. If each channel is handled manually, automation gains disappear. If every channel receives the same copy, performance suffers.
This is why an automated blog system has to be designed as distribution infrastructure, not just a post generator. The prior bl0ggers.com article on automated blog posting platform architecture is useful here because it treats publishing as a workflow of approvals, integrations, scheduling, and measurement instead of a single CMS push.
Channel packaging is not copy paste
Channel context changes the asset.
A blog post can explain. A newsletter must earn the click and respect the inbox. A LinkedIn post needs a sharp opening and a clear reader payoff. A podcast brief needs segment flow, not paragraphs. A CMS excerpt needs precision. A sponsor mention may need approval language.
A distribution workflow should create channel packages from the approved source asset, not from an unapproved draft. That avoids a common bug: a social post or email version preserves a claim that the editor removed from the article.
Channel package examples:
- CMS title, slug, excerpt, meta description, hero image prompt
- newsletter subject line, preview text, intro, body teaser, CTA
- social post variants by platform
- podcast talking points and segment outline
- internal enablement summary for sales or customer success
Scheduling needs rollback paths
Automation should schedule publication, but it also needs stop buttons.
Useful rollback controls include:
- pause scheduled publish
- unpublish or revert to draft
- replace scheduled newsletter content
- regenerate only channel package, not approved article
- notify owner when a publish job fails
- preserve audit trail of who approved what
What breaks in practice is that publishing systems optimize for forward motion. Real operations need reversibility. A sponsor changes copy. A launch slips. A source asks for a correction. A legal reviewer catches an issue two hours before send time.
If the workflow cannot pause, replace, or roll back, the team will move critical work back into manual tools.
Measurement closes the workflow loop
A content automation workflow without measurement is just faster guessing.
Measurement should not be limited to pageviews. Publishing teams need two classes of metrics: workflow health and content performance. One tells you whether the system is operating. The other tells you whether the content is useful.
Metrics that expose workflow health
Workflow health metrics show where the machine is getting stuck.
Track:
- time from idea to brief approval
- time from brief to generated draft
- time in editorial review
- revision count per asset
- rejection rate by content type
- gate failure rate
- percentage of assets escalated to deep review
- scheduled publish failures
- refresh backlog size
These metrics are not about punishing the team. They identify bottlenecks. If editorial review time doubles, maybe the drafts are weak. Maybe the editor is overloaded. Maybe too much content is routed to the deep lane. The data changes the conversation.
Feedback should update the brief
Content performance should feed the next input, not sit in a dashboard nobody uses.
For example:
- Articles with high impressions and low clicks may need title and angle changes.
- Newsletters with strong opens and weak clicks may need better body framing.
- Posts with high engagement but low conversion may need a stronger next step.
- Articles that rank but do not retain readers may need examples and structure revisions.
- Assets that trigger support questions may need clearer expectations.
The workflow should convert those learnings into brief fields. If a format works, make it a template. If an angle fails, mark it. If a CTA underperforms, test another. Automation becomes useful when it remembers.
What breaks when content automation is implemented badly
Bad content automation does not usually fail dramatically. It fails through accumulation.
The team publishes more, but the work feels thinner. Editors become cleanup crews. The brand voice drifts toward generic. Review queues become overloaded. Performance dashboards grow, but the brief does not improve. Eventually, someone declares that AI content does not work, when the real issue was poor workflow design.
Related reading from our network: security operations teams see a similar pattern when more signals create more noise unless ownership and response are defined, which is why the workflow framing in encrypted messaging security operations maps surprisingly well to publishing operations.
Failure mode one content sameness
Content sameness is the most visible failure. Every article has the same structure, the same safe statements, the same middle-of-the-road advice, and the same bland conclusion.
This usually happens when the system optimizes for draft completion instead of editorial point of view.
Causes include:
- briefs do not include a specific reader pain
- prompts ask for comprehensive guides instead of decisions
- source material is generic
- editors only proofread instead of sharpening the argument
- performance feedback does not influence future briefs
The fix is not to demand more creativity from the model. The fix is to encode stronger inputs: clearer audience, sharper angle, approved examples, and a required practical stance.
Failure mode two review bottlenecks
The second failure is review collapse. Automation creates more drafts than humans can inspect. The editor becomes the constraint, and the queue gets messy.
Symptoms include:
- approved drafts sitting unpublished
- low-risk posts waiting behind strategic assets
- rushed reviews near deadlines
- comments spread across docs, Slack, and CMS fields
- inconsistent decisions across reviewers
- last-minute rewrites because the brief was weak
The fix is routing. Use review lanes, automated gates, and explicit escalation rules. Do not ask one editor to manually compensate for an undefined system.
Implementation sequence for 2026 content teams

The practical question is how to implement a content automation workflow without stopping publishing for a quarter.
Do not rebuild everything at once. Pick a narrow content line, define the state machine, add gates, and expand from there.
Start with one content line
Choose one content line with enough volume to matter but not enough risk to damage the business if the first version is imperfect.
Good candidates:
- weekly SEO support articles
- newsletter summaries from approved posts
- podcast episode show notes
- community update posts
- product education articles
- partner roundup content
Avoid starting with your highest-stakes pages. Do not begin with homepage copy, pricing pages, regulated claims, or executive thought leadership if the workflow is untested.
Add automation in layers
A practical implementation sequence:
- Map current production. List every step from idea to published asset. Include hidden steps like Slack approval and manual CMS formatting.
- Define states and owners. Decide what states exist and who can move assets between them.
- Standardize briefs. Create a brief template with audience, intent, sources, risk level, and CTA.
- Generate drafts from approved briefs only. Do not let random ideas trigger production.
- Add automated gates. Check required fields, forbidden claims, links, metadata, and placeholders.
- Create review lanes. Route low-risk and high-risk content differently.
- Package approved content by channel. Generate newsletter, social, podcast, or CMS variants from the approved source asset.
- Add scheduling and rollback. Make publishing controllable, not just automatic.
- Measure workflow health. Track review time, gate failures, revision count, and publish errors.
- Feed performance back into briefs. Turn learning into templates, not tribal memory.
Practical rule: Automate the next stable step, not the step you still argue about in every editorial meeting.
This sequence keeps the project grounded. You are not adopting AI as a belief system. You are reducing operational waste while keeping editorial control visible.
Where bl0ggers.com fits in the workflow
bl0ggers.com is built for teams that want AI-assisted publishing without handing the entire process to a black box.
That matters because content teams rarely need just more text. They need research turned into publishable assets, review queues that respect human judgment, and distribution paths that support blogs, podcasts, newsletters, and owned media properties.
Human in the loop by default
A useful AI publishing system should make review natural. It should not require teams to export drafts, paste them into separate docs, lose metadata, then paste them back into a CMS.
Human-in-the-loop by default means:
- drafts can be reviewed before publication
- personas and editorial context can guide generation
- approval steps are part of the workflow
- generated assets can support multiple formats
- automation can connect to publishing destinations
- humans can intervene when risk or quality requires it
The point is not to slow down automation. The point is to keep the right decisions in the right hands.
Practical fit for publishers and operators
For content marketers, creators, newsletter operators, and publishers, the useful product question is simple: can the system help you move from research to reviewed content to distribution without inventing a new manual process around it?
bl0ggers.com is a fit when you need:
- persona-led content production
- generated article workflows
- podcast or newsletter content support
- optional human review
- subdomain publishing patterns
- webhook-based automation
- repeatable review and distribution paths
It is not a replacement for editorial direction. It is infrastructure for teams that already know content quality matters and want the workflow to scale without losing the human layer.
Closing checklist for a durable content automation workflow
A durable content automation workflow is not the most automated system. It is the system where automation, review, publishing, and learning reinforce each other.
If the workflow only creates drafts, it will produce more editorial cleanup. If it only adds approvals, it will slow the team down. If it only pushes to channels, it will spread mistakes faster. The architecture has to connect the full loop.
What works
What works in production:
- explicit content states
- approved briefs before generation
- source policies that prevent invented authority
- automated gates for repeatable checks
- review lanes based on risk
- humans assigned to judgment, not formatting
- channel packages generated from approved assets
- scheduling with rollback controls
- workflow metrics alongside content metrics
- performance feedback that updates templates and briefs
What fails
What fails in production:
- prompt libraries with no workflow state
- one approval step for every content type
- direct publishing without review controls
- generic briefs that produce generic articles
- editors used as cleanup buffers
- distribution copy generated from unapproved drafts
- dashboards that never change the next brief
- automation that cannot pause, revert, or escalate
The teams that win with content automation in 2026 will not be the teams that publish the most unreviewed words. They will be the teams with the clearest content automation workflow: defined state, useful gates, review where it matters, distribution with context, and measurement that improves the next cycle.
Try bl0ggers.com
bl0ggers.com is for content teams, creators, and publishers who want to use AI to increase output without giving up editorial control. Try bl0ggers.com.