
An automated blog posting platform sounds like a simple productivity upgrade until the first bad article goes live, the newsletter repeats the same claim twice, or a sponsor complains that the wrong version of a post was promoted.
Teams think the problem is posting faster. The real problem is publishing with enough structure that speed does not create editorial debt.
That changes the conversation. You are not buying a button that sends AI text to WordPress. You are designing a content operations system: inputs, review lanes, quality gates, approvals, distribution rules, analytics, and rollback paths.
In 2026, the practical question is not whether AI can draft blog posts. It can. The practical question is whether your team can run an automated blog posting platform without losing voice, trust, search quality, or accountability.
Table of contents
- Why an automated blog posting platform is workflow infrastructure
- The operating model: from idea to published asset
- Where automation belongs and where it should stop
- Quality gates that prevent bad automation
- Approval lanes, roles, and accountability
- Distribution, scheduling, and channel rules
- Integrations: CMS, newsletters, webhooks, and analytics
- Measurement: what to track beyond traffic
- Failure modes when automated blog posting is implemented badly
- How bl0ggers.com fits into the architecture
- Implementation checklist for the first 30 days
- Closing: choose an automated blog posting platform, not a posting bot
Why an automated blog posting platform is workflow infrastructure
Publishing velocity is not the same as publishing control
The mistake teams make is treating an automated blog posting platform as a faster CMS user. Draft goes in, post comes out, traffic hopefully follows.
That is the shallow version. It works for demos and breaks in production.
A real publishing operation has constraints: brand voice, topical authority, audience promises, legal sensitivity, customer claims, sponsor obligations, SEO intent, newsletter timing, internal approvals, and sometimes regional compliance. If automation ignores those constraints, it does not create scale. It creates cleanup work.
A useful way to think about it is this: automation should increase throughput while preserving the editorial decisions that made the publication worth reading in the first place.
The platform should answer operational questions:
- Who requested this article?
- Which persona or audience segment is it for?
- What sources, notes, or product details were used?
- Which reviewer approved it?
- Which quality gates passed?
- Where was it distributed?
- What happens if it needs to be updated or pulled?
If those answers live in Slack threads and memory, you do not have a platform. You have a content generator connected to a publish button.
The real control plane is state
State is the difference between an automated workflow and a pile of automation.
A post should move through visible states: idea, briefed, generated, edited, reviewed, approved, scheduled, published, distributed, measured, refreshed, archived. Each state should have owners, timestamps, and rules.
That changes how the team works. Editors stop asking whether something is ready. Operators stop checking five tools to know what shipped. Writers stop getting surprised by last-minute changes. Leadership can see capacity without asking for a spreadsheet.
Practical rule: If a post can go from generated to published without changing state and leaving an audit trail, your automation is too powerful for its own governance.
This is why the best automated publishing systems look less like text tools and more like workflow engines with editorial context.
The operating model: from idea to published asset
Inputs should be structured before generation
Bad automation starts with vague prompts. Good automation starts with structured inputs.
Before generation, define the minimum viable brief. For most content teams, that includes:
- Topic or working title
- Primary keyword and secondary search intent
- Audience segment or persona
- Funnel stage or business goal
- Required claims or product positioning
- Forbidden claims or legal boundaries
- Source notes, interviews, transcripts, or product docs
- Internal links to consider
- Distribution destination
- Reviewer or approval lane
The brief is not bureaucracy. It is the contract between strategy and automation.
If your team already thinks about review architecture, the same principles apply here. The deeper workflow argument is covered in our prior post on human-in-the-loop AI publishing workflow architecture, but the short version is simple: automation needs human intent in a structured format before it can produce reliable output.
Unstructured prompts create unstructured risk. The model fills gaps with generic assumptions. Sometimes those assumptions are harmless. Sometimes they create claims your sales team would never make, examples your audience does not care about, or references your editor now has to unwind.
States make automation observable
Here is a practical workflow sequence for an automated blog posting platform:
- Capture the content request with topic, persona, and objective.
- Generate or attach a structured brief.
- Produce the first draft with metadata attached.
- Run automated checks for formatting, duplication, internal links, keyword coverage, and policy flags.
- Route the draft to the correct human reviewer.
- Apply edits and require approval before scheduling.
- Publish to the CMS or hosted subdomain.
- Trigger distribution to newsletter, social, RSS, or partner channels.
- Collect performance and quality signals.
- Queue refreshes when posts age, underperform, or become inaccurate.
The important part is not that every team uses the same labels. The important part is that every post has a visible lifecycle.
A comparison makes the distinction clear:
| Area | Posting bot | Automated blog posting platform |
|---|---|---|
| Input | Prompt or topic | Structured brief with audience and intent |
| Review | Optional or manual | Routed by risk, role, and status |
| Publishing | Direct push to CMS | Scheduled state transition with approval |
| Distribution | Same copy everywhere | Channel-specific packaging |
| Audit trail | Minimal | Owner, state, timestamp, and decision history |
| Measurement | Traffic only | Throughput, quality, engagement, refresh needs |
The mistake teams make is trying to fix a posting bot with more prompts. The better move is to fix the operating model.
Where automation belongs and where it should stop
Work that should be automated
Automation is strongest when the task is repetitive, bounded, and easy to validate.
In a publishing workflow, that usually means:
- Generating outlines from approved briefs
- Creating first drafts from source material
- Formatting markdown or CMS blocks
- Suggesting titles, meta descriptions, and excerpts
- Checking whether required sections exist
- Detecting broken links or missing images
- Preparing newsletter summaries
- Scheduling posts within approved cadence windows
- Updating status fields and notifying reviewers
- Creating refresh candidates from analytics signals
These jobs are operationally useful because they reduce handoff friction. They do not require the machine to decide what the brand believes.
Related reading from our network: teams using AI publishing for local coordination face similar trust and routing problems in AI publishing community building, even though the audience and use case are different.
Judgment that should stay human
Human review matters most where the cost of being wrong is high or the signal is contextual.
Keep humans responsible for:
- Strategic positioning
- Sensitive claims
- Editorial voice
- Original insight
- Customer stories
- Competitive comparisons
- Legal or compliance-sensitive language
- Final approval for high-visibility channels
This is not anti-automation. It is basic risk management.
Practical rule: Automate the work around judgment before you automate the judgment itself.
The platform should make human review cheaper and faster, not optional by default. That means reviewers should see what changed, why the article exists, which gates passed, and which issues require attention.
What fails is the all-or-nothing model: either AI drafts everything and publishes directly, or every article gets dragged through the same slow manual process. Mature teams use risk tiers.
For example:
- Low-risk glossary post: automated draft, light editorial review, scheduled publish.
- Product comparison post: automated draft, product marketing review, editor approval.
- Regulated industry post: source-grounded draft, legal review, final editor approval.
Same platform. Different lanes.
Quality gates that prevent bad automation

Gate types that matter in production
Quality gates are where an automated blog posting platform earns its keep. They prevent the system from turning volume into brand damage.
Useful gates include:
- Brief completeness gate: required fields are present before generation.
- Source grounding gate: draft cites or reflects approved source material.
- Structure gate: article includes required sections, headings, metadata, and CTA.
- SEO gate: primary topic is covered naturally without stuffing.
- Internal linking gate: approved links are used in context.
- Brand voice gate: tone matches publication rules.
- Risk gate: sensitive claims or restricted topics trigger review.
- Duplication gate: post is not too similar to existing content.
- Distribution gate: channel assets exist before scheduling.
Do not treat gates as perfection machines. Treat them as triage.
A useful gate does one of three things: pass, flag, or block. If every issue blocks, the workflow slows down. If every issue only warns, people ignore the system.
Pass and fail criteria should be explicit
The practical question is not whether quality matters. Everyone agrees it does. The practical question is who defines quality in a way the workflow can enforce.
For example:
| Gate | Pass condition | Flag condition | Block condition |
|---|---|---|---|
| Metadata | Title, slug, excerpt, tags present | Excerpt too long | Missing title or slug |
| Claims | Uses approved product language | Unverified comparison | Legal or medical claim without review |
| Links | Required links placed naturally | Too many repeated anchors | Broken internal link |
| Voice | Matches style profile | Slightly generic intro | Off-brand or misleading framing |
| Distribution | Newsletter summary ready | Social copy missing | Publish requested before approval |
Practical rule: A quality gate without a defined action is just a comment that the team will eventually ignore.
The strongest gates combine automated checks with human review. Automated checks catch missing fields, broken links, formatting errors, repeated phrases, and obvious policy flags. Humans catch weak arguments, awkward framing, unsupported conclusions, and brand risk.
That is the balance. Use software to reduce reviewer fatigue. Do not use it to pretend review is unnecessary.
Approval lanes, roles, and accountability
Assign ownership by risk, not ego
Approval workflows often fail because every stakeholder wants visibility and nobody wants to own the decision.
The platform should separate visibility from approval. Many people can watch a post. Few people should block it.
A simple role model works:
- Requester: creates the content need and business context.
- Operator: manages queue, metadata, schedule, and routing.
- Editor: owns clarity, voice, and quality.
- Subject matter reviewer: checks technical or product accuracy.
- Approver: accepts final publishing risk.
For small teams, one person may hold several roles. That is fine. The workflow still needs the roles to be explicit.
This is where many content teams benefit from thinking beyond traditional CMS permissions. WordPress roles can say who is allowed to publish. They usually do not explain why this article is ready, what review lane it passed, or whether the newsletter version is approved.
Escalation paths prevent silent failure
What breaks in practice is not always bad content. Sometimes it is stuck content.
A draft sits in review for nine days. A product launch article misses the embargo. A newsletter gets delayed because nobody approved the subject line. A contractor assumes a post was rejected when it was only waiting for a metadata fix.
An automated blog posting platform should make stuck states obvious:
- Draft waiting for review longer than the SLA
- Reviewer assigned but inactive
- Approval requested after scheduled publish time
- Distribution assets missing
- High-risk flag unresolved
- Published post missing measurement tags
The workflow should notify, reassign, or escalate based on rules.
Example escalation logic:
review_lane: product_marketing
sla_hours: 48
if_overdue:
notify: editor_owner
escalate_after_hours: 72
escalate_to: content_lead
if_high_risk_claim: true
require_approval_from: subject_matter_reviewer
The exact syntax does not matter. The principle does.
If a workflow can silently fail, it will.
Distribution, scheduling, and channel rules
Channel-specific packaging beats one-click syndication
The UI is not the publishing system. A blog post is usually only the primary asset.
A mature workflow generates or queues channel-specific derivatives:
- Blog article
- Newsletter intro
- Subject line options
- Social snippets
- LinkedIn post
- RSS excerpt
- Podcast notes, if relevant
- Internal enablement summary
- Refresh reminder
One-click syndication sounds efficient, but it often creates lazy distribution. The same headline, excerpt, and CTA get pushed everywhere. That may be acceptable for a low-stakes update. It is weak for campaigns, newsletters, and creator-led publications.
A better automated blog posting platform lets you define channel rules. For example, newsletter copy can be warmer and more direct, while the blog introduction stays search-oriented. Social copy can lead with a contrarian point. Internal summaries can focus on sales enablement.
Cadence needs constraints
Publishing more often is not always better. If automation lets you post ten times per day, that does not mean your audience wants ten posts per day.
Set cadence constraints:
- Maximum posts per day per publication
- Minimum spacing between posts on similar topics
- Newsletter send windows
- Campaign blackout dates
- Review deadlines before launch events
- Refresh windows for aging posts
- Queue priority rules
This is especially important for publishers and newsletter operators. Audience trust is partly a cadence promise. If readers expect one high-signal email per week and suddenly receive five AI-assisted digests, the workflow has damaged the relationship.
Related reading from our network: monetized AI content businesses also have operational constraints around access, payment, and support, which are covered in AI publishing cryptocurrency payment architecture.
The same lesson applies here: distribution is not just output. It is state, timing, entitlement, and support.
Integrations: CMS, newsletters, webhooks, and analytics
Map the integration surface before launch
Most teams underestimate integration work. They ask whether the platform can publish to the CMS. That is only one piece.
Map the full surface:
| System | Why it matters | Common failure |
|---|---|---|
| CMS | Final article hosting | Formatting drift or duplicate slugs |
| Newsletter tool | Audience distribution | Wrong segment or missing preview |
| Analytics | Measurement and refresh triggers | No campaign tags or content IDs |
| Asset library | Images and media | Missing alt text or licensing context |
| Project management | Visibility | Status split across tools |
| Webhooks | Automation between systems | Repeated events or missed retries |
| Identity | Permissions and approval | Contractors can publish too broadly |
If your workflow already uses AI drafts but lacks lifecycle coordination, our guide to AI blog publishing software workflow architecture goes deeper on how review queues, approvals, and distribution should connect.
The practical move is to draw the content object. What fields travel with the article from request to publication? Which systems can mutate those fields? Which system is the source of truth?
A content object might include:
{
"content_id": "post_2026_0612_004",
"status": "approved_for_schedule",
"persona": "newsletter_operator",
"primary_keyword": "automated blog posting platform",
"owner": "editorial_ops",
"review_lane": "standard_editorial",
"cms_slug": "automated-blog-posting-platform",
"distribution": ["blog", "newsletter", "rss"],
"risk_level": "medium"
}
That object is the operational spine.
Retries and idempotency are editorial safeguards
Technical reliability matters because publishing errors are public.
If a webhook fires twice, do you create two posts? If the CMS times out after receiving the article, do you retry and duplicate it? If a newsletter send fails, do you know whether the blog post is live but the email is not?
These are not abstract engineering concerns. They become editorial incidents.
A reliable automated blog posting platform should support:
- Stable content IDs
- Idempotent publish actions
- Retry policies with backoff
- Error logs visible to operators
- Draft versus publish separation
- Rollback or unpublish paths
- Manual override with audit trail
Related reading from our network: security teams think about similar workflow boundaries when connecting AI publishing to detection and response systems in AI publishing threat detection as a SOC workflow.
The analogy is useful. In both cases, disconnected automation creates noise. Connected workflow creates control.
Practical rule: Treat publish events like production deployments. They need IDs, logs, retries, owners, and rollback paths.
Measurement: what to track beyond traffic
Production metrics expose bottlenecks
Traffic is a lagging indicator. It matters, but it does not tell you whether your publishing system is healthy.
Track production metrics:
- Brief-to-draft time
- Draft-to-review time
- Review cycle count
- Approval time by lane
- Posts blocked by each gate
- Overdue review percentage
- Publish success and failure events
- Distribution completion rate
- Refresh backlog
These metrics show where work gets stuck. If draft generation takes two minutes but review takes eight days, your bottleneck is not writing. It is decision routing.
If half your posts fail the same metadata gate, the issue is not editor quality. The issue is upstream brief design or template configuration.
Quality metrics protect the brand
Quality is harder to measure than throughput, but it is not invisible.
Useful quality signals include:
- Editor revision depth
- Number of factual corrections per post
- Posts requiring post-publication fixes
- Search impressions by topic cluster
- Newsletter unsubscribe or complaint patterns
- Average engaged time
- Conversion assisted by content type
- Refresh performance after updates
- Internal stakeholder correction requests
Do not reduce content quality to a single score. Composite scores can hide the exact problem. Operators need actionable signals.
A practical dashboard separates speed, quality, and business outcome:
| Metric group | Example question | Operator action |
|---|---|---|
| Throughput | How many approved posts shipped? | Adjust queue capacity |
| Review | Where are drafts stuck? | Reassign or change lane rules |
| Quality | Which posts needed corrections? | Tighten gates or sources |
| Distribution | Did all channels complete? | Fix integration failures |
| Outcome | Which topics worked? | Update briefs and content strategy |
The mistake teams make is celebrating output without measuring rework. If publishing volume rises but corrections, unsubscribes, and reviewer fatigue rise with it, the system is not scaling cleanly.
Failure modes when automated blog posting is implemented badly
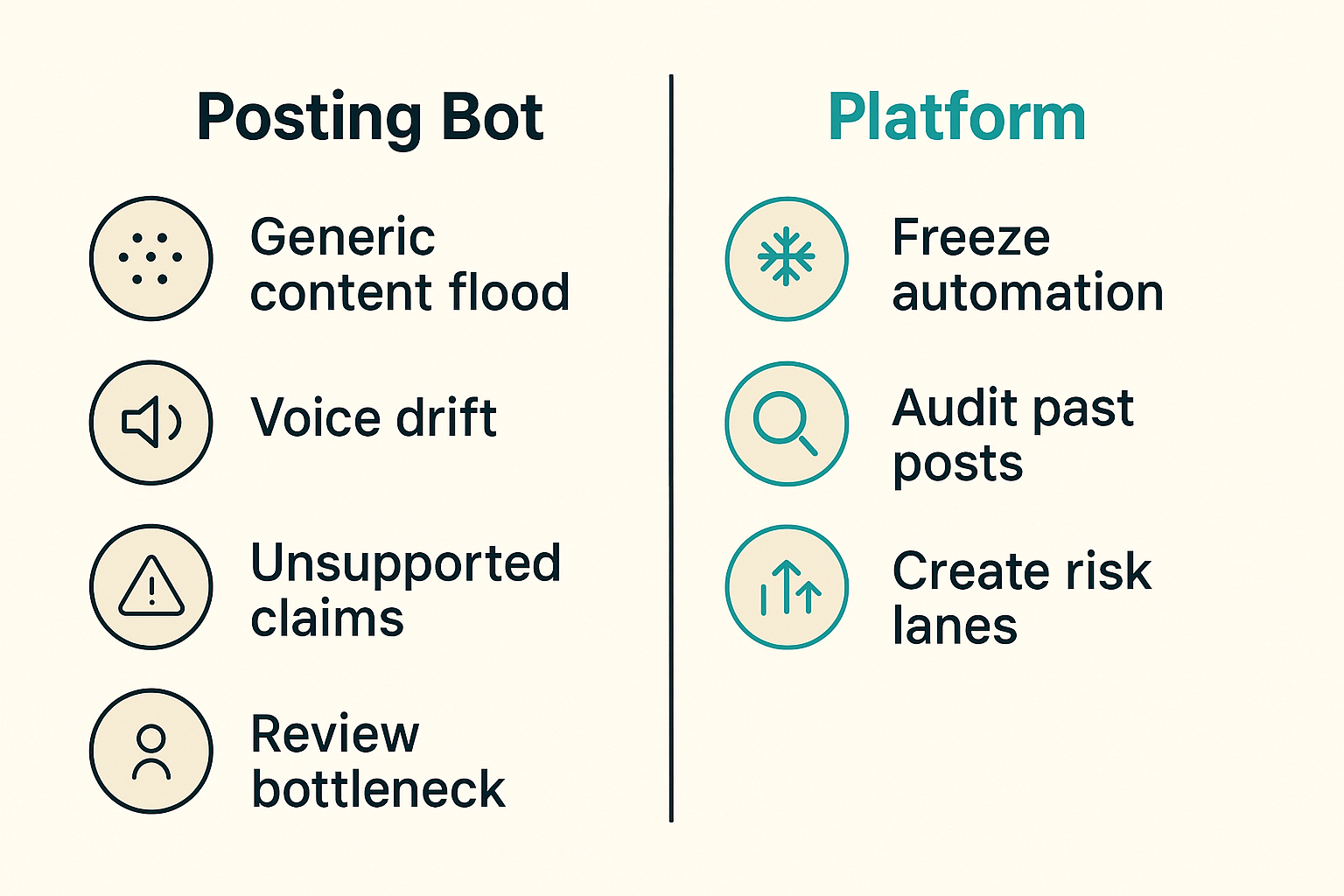
What breaks in practice
Automated publishing fails in predictable ways.
The most common failure modes:
- Generic content flood: the site fills with articles that technically match keywords but say nothing useful.
- Voice drift: posts slowly stop sounding like the publication.
- Unsupported claims: generated language overstates product capabilities or makes risky comparisons.
- Review bottleneck: AI creates more drafts than editors can evaluate.
- Duplicate topics: similar articles compete with each other because the queue lacks topic memory.
- Broken distribution: blog posts go live but newsletter and social assets are missing.
- Metadata rot: slugs, tags, excerpts, canonical rules, and schema become inconsistent.
- No refresh loop: old posts stay live after the product, market, or policy changes.
- Accountability blur: nobody knows who approved what.
What breaks in practice is usually not the model alone. It is the gap between generated content and operational control.
Recovery patterns that actually help
If your system is already messy, do not start by changing models. Start by tightening workflow.
What works:
- Freeze direct-to-publish automation until states are defined.
- Audit the last 50 posts for corrections, duplication, and approval gaps.
- Create risk lanes and route high-risk topics differently.
- Require structured briefs for new content.
- Add gates for metadata, links, claims, and distribution readiness.
- Build a refresh queue for outdated high-traffic posts.
- Give one operator ownership of the publishing queue.
What fails:
- Adding more prompt instructions without changing review.
- Asking editors to manually police every automation error.
- Publishing first and fixing later as a default behavior.
- Measuring only article count.
- Letting every stakeholder approve, but nobody own.
A useful way to think about recovery is to reduce blast radius. Automation should be allowed to act where failure is cheap and reversible. It should slow down where failure is public, expensive, or trust-damaging.
How bl0ggers.com fits into the architecture
Product fit for human-in-the-loop publishing
bl0ggers.com is built around the idea that AI publishing should be automated without becoming uncontrolled. That matters for content teams, creators, and publishers who want more output, but still need review lanes, editorial judgment, and workflow visibility.
The useful fit is architectural:
- AI-generated research can become blogs, newsletters, podcasts, or subdomain publications.
- Human review can remain part of the workflow instead of being bolted on afterward.
- Persona-led content can be organized around audiences rather than one generic content queue.
- Automation can connect to publishing and distribution workflows through integrations and webhooks.
- Operators can think in terms of queues, approvals, and publishing states.
This is not about replacing editors. It is about removing avoidable production drag so editors spend less time formatting drafts and more time improving the work.
The product is most relevant when the team already feels the ceiling of manual publishing: too many ideas, too many channels, inconsistent review, slow approvals, and no clean way to turn AI-assisted drafts into controlled output.
When to adopt a platform instead of scripts
Scripts are fine at the beginning. A simple automation that turns a transcript into a draft can save hours.
But scripts become fragile when:
- More than one person needs to approve content.
- Multiple publications or subdomains are involved.
- Different personas require different voice and structure.
- Newsletter and blog workflows need to stay aligned.
- You need audit trails.
- You need repeatable quality gates.
- You need a queue that non-technical operators can manage.
That is the point where an automated blog posting platform becomes more useful than a collection of scripts.
If you are evaluating that transition, start with the live workflow, not the feature list. Write down how a content request becomes a published asset today. Then mark every handoff, delay, rework loop, and unclear decision. The platform should remove or formalize those points.
Implementation checklist for the first 30 days
A week-by-week rollout sequence
Do not roll out full automation across the whole publication on day one. That is how teams create cleanup projects.
Use a staged rollout:
- Week 1: Map the current workflow. Identify content types, owners, review steps, approval rules, and distribution channels.
- Week 1: Define required brief fields for each content type.
- Week 2: Create three risk lanes: low, standard, and high.
- Week 2: Configure gates for metadata, links, structure, and claims.
- Week 3: Run AI-assisted drafting for one content type only.
- Week 3: Keep human approval required before scheduling.
- Week 4: Add distribution packaging for newsletter or social.
- Week 4: Review metrics, corrections, and bottlenecks before expanding.
This sequence is intentionally conservative. The goal is not to prove AI can create drafts. The goal is to prove the workflow can absorb automation safely.
Decision questions before scaling
Before increasing volume, answer these questions:
- Which content types are safe for lighter review?
- Which topics always require subject matter approval?
- What quality gates are blocking too much or too little?
- Can operators see every stuck post?
- Are published articles easy to update or unpublish?
- Are distribution assets created before the publish date?
- Are analytics tied back to content IDs and briefs?
- Are editors spending less time on mechanical cleanup?
- Is the audience response stable or improving?
If the answers are unclear, slow down. You do not need more output yet. You need a cleaner system.
Practical rule: Scale the lane that is already controlled. Do not scale the lane that still depends on heroics.
Closing: choose an automated blog posting platform, not a posting bot
Final operator take
An automated blog posting platform should not be judged by how quickly it can push text to a CMS. That is table stakes.
Judge it by whether it preserves the operating discipline of a real publication: structured inputs, visible states, review lanes, quality gates, approval accountability, reliable integrations, distribution control, and measurement.
The teams that win with AI publishing will not be the teams that remove humans from the process as quickly as possible. They will be the teams that put humans in the right places and automate the rest.
That changes the conversation. The goal is not more posts. The goal is a publishing system that can produce more useful work without losing editorial control.
Try bl0ggers.com
bl0ggers.com is for content teams, creators, and publishers who want to use AI to increase output without giving up editorial control. Try bl0ggers.com.