
Your content team does not need another place to paste prompts.
That is the easy part. The hard part is turning AI-assisted drafts into approved, useful, brand-safe content that ships on schedule across blogs, newsletters, and social channels. That is where most AI blog publishing software either helps or becomes another messy folder of half-reviewed drafts.
Teams think the problem is content generation. The real problem is publishing control.
In 2026, the practical question is not whether AI can produce a blog draft. It can. The question is whether your team can manage briefs, sources, review lanes, approvals, edits, publishing states, distribution, and measurement without creating a second hidden CMS inside Slack, Google Docs, and spreadsheets. That changes the conversation. AI blog publishing software is not a writing toy. It is an operating system for content throughput.
Table of contents
- Why AI Blog Publishing Software Is a Workflow System
- The Operating Model: From Prompt to Published Asset
- Reference Architecture for AI Blog Publishing Software
- Quality Gates That Keep Scale From Becoming Cleanup
- Human Review Lanes and Approval Logic
- Automation That Helps Without Hiding Failure
- Measurement: What to Track After Publishing
- What Breaks When Teams Implement It Badly
- Build or Buy: Choosing AI Blog Publishing Software
- Implementation Sequence for Content Teams
- Where bl0ggers.com Fits
Why AI Blog Publishing Software Is a Workflow System
The Mistake Teams Make
The mistake teams make is evaluating AI blog publishing software like it is only a generator. They ask whether the tool can write a post, produce a title, suggest keywords, or create outlines. Those features matter, but they do not solve the operational problem.
The operational problem is repeatability. Can the same team brief the same kind of article, apply the same review criteria, publish to the same destinations, and learn from the same measurement loop every week?
A useful way to think about it is this: generation creates inventory. Publishing turns inventory into assets. If your workflow cannot convert drafts into approved assets, more generation just creates a larger backlog.
Practical rule: Do not buy AI blog publishing software to produce more drafts. Buy or build it to reduce the distance between idea, approval, publication, and learning.
The Publishing Surface Area
Modern publishing has more surfaces than the blog post itself. A single article may become a newsletter segment, a LinkedIn post, a podcast outline, an internal enablement note, a short-form script, and a campaign landing page. Each surface has a different format, owner, risk profile, and publishing cadence.
What breaks in practice is that teams treat the blog as the source of truth, then manually reshape content everywhere else. The result is stale snippets, inconsistent messaging, and no clean record of what shipped.
Good AI publishing software should understand assets, not just text. It should track the source brief, generated variants, review status, publication target, canonical URL, campaign context, and post-publish performance.
Where AI Changes the Bottleneck
Before AI, the bottleneck was often drafting capacity. After AI, the bottleneck moves to judgment: which ideas deserve coverage, which drafts are accurate, which claims need review, and which channels should receive which version.
That changes team design. Editors become workflow controllers. Subject matter experts become exception handlers. Content marketers become distribution operators. The software should support that shift instead of pretending one person will manually inspect everything forever.
The Operating Model: From Prompt to Published Asset
Inputs Before Generation
Prompt quality matters, but prompts are only one input. A production workflow should start with structured context:
- target reader and funnel stage
- keyword or topic cluster
- source material and claims that are allowed
- prohibited claims or sensitive topics
- brand voice and examples
- required call to action
- publication channel and format
- reviewer or approver
If these inputs live in a prompt pasted by memory, the workflow will drift. If they live in reusable templates, the team can improve the system over time.
For a deeper adjacent breakdown of review routing and quality gates, the prior guide on human-in-the-loop AI publishing workflow architecture is useful because it treats humans as part of the system, not as a last-minute cleanup crew.
Review Lanes After Generation
The next layer is review. Not every asset needs the same review. A low-risk evergreen post may need editorial approval only. A product comparison may need product marketing. A legal or finance topic may need a subject matter expert. A brand-sensitive executive byline may need a senior editor.
Review lanes should be explicit:
- editorial review for structure, clarity, and usefulness
- factual review for claims, examples, and technical accuracy
- SEO review for intent, internal links, metadata, and cannibalization
- brand review for voice, positioning, and sensitive language
- final approval for publishing readiness
Related reading from our network: AI Publishing Shipping Software makes a similar point from a launch workflow angle: shipping faster only works when the launch system has control points.
Output Channels and Ownership
Output is where vague ownership becomes expensive. If a post is approved, who publishes it? Who adapts it for email? Who checks the canonical link? Who monitors comments or replies? Who updates it if a product feature changes?
The practical question is not whether AI can draft channel variants. It can. The question is whether your software can keep those variants connected to the original asset and show who owns each step.
Reference Architecture for AI Blog Publishing Software
Core Components
A practical AI blog publishing software stack has six core components:
- Intake: captures ideas, briefs, keywords, source links, and campaign context.
- Generation: creates outlines, drafts, metadata, variants, and repurposed assets.
- Review: routes work through humans and automated checks.
- Approval: records who approved what and when.
- Publishing: pushes content to CMS, newsletter tools, feeds, or subdomains.
- Measurement: tracks performance and feeds learning back into planning.
The mistake teams make is buying generation and then duct-taping the other five layers together. That can work for a solo creator. It usually fails for teams with multiple reviewers, multiple channels, or any compliance concerns.
The State Model
State is the hidden architecture. Every asset needs a status that means something operationally. For example:
asset_state:
- idea
- brief_ready
- draft_generated
- editorial_review
- fact_review
- revision_requested
- approved
- scheduled
- published
- updated
- archived
This looks simple, but it prevents chaos. Without states, people ask the same questions repeatedly: Is this ready? Who has it? Did we publish it? Which version is live?
Practical rule: If your team cannot describe the state of every asset in one sentence, your publishing workflow is not ready to scale.
Integration Boundaries
Do not force one tool to be everything. Your AI publishing layer should integrate with the systems that already own important work: CMS, analytics, email service provider, project management, customer relationship management, and collaboration tools.
The boundary should be clear. The AI publishing system owns content workflow state. The CMS owns rendering and public URLs. Analytics owns traffic and conversion data. Email software owns subscriber delivery. When boundaries blur, debugging becomes painful.
Quality Gates That Keep Scale From Becoming Cleanup
Editorial QA
Editorial QA is not grammar checking. It is the decision that a piece deserves to exist. Editors should ask:
- Does the article answer a real reader problem?
- Is the structure useful, or just complete-looking?
- Does the intro frame a concrete pain point?
- Are examples specific enough for the audience?
- Does the article say anything the team is willing to stand behind?
Many AI drafts are syntactically clean and operationally useless. They summarize the obvious. They avoid hard tradeoffs. They use confident language without practical specificity. Editorial QA is where that gets fixed.
SEO and Factual QA
SEO QA should not mean stuffing the keyword into every paragraph. It means checking intent alignment, topical depth, internal link relevance, metadata, title clarity, and whether the asset competes with existing pages.
Factual QA is separate. It checks claims, dates, product details, technical steps, pricing references, and anything that could mislead a reader. In AI-assisted workflows, factual QA matters because fluent text can hide uncertainty.
A lightweight checklist works better than vague review comments:
- keyword appears naturally in title, intro, headings, and close
- search intent is addressed directly
- claims are either sourced, qualified, or removed
- examples match the target reader
- metadata is written, not auto-filled blindly
- internal links are relevant and not forced
Brand and Legal QA
Brand QA protects positioning. Legal QA protects risk. They should not be the same lane unless the team is tiny.
Brand review catches tone, promise level, audience mismatch, and positioning conflicts. Legal review catches regulated claims, copyright issues, disclosure requirements, and privacy-sensitive content. Most blog posts will not need legal review, but the routing logic should exist before a sensitive asset appears.
Practical rule: Review everything lightly by default, then route high-risk content heavily by exception. Full manual review for every asset sounds safe until it blocks the entire publishing calendar.
Human Review Lanes and Approval Logic
When Humans Must Intervene
Human review should be triggered by risk, not habit. Humans must intervene when content includes:
- original claims about customers, competitors, revenue, health, finance, or security
- product roadmap details or feature promises
- legal, compliance, or policy interpretations
- executive voice or founder perspective
- sensitive community issues
- technical instructions that could cause harm if wrong
This is where human-in-the-loop is not a slogan. It is routing logic. The system should know when to pause automation and ask a person with context.
How to Route by Risk
A simple risk matrix is enough for most teams:
| Content type | Default route | Extra reviewer | Automation level |
|---|---|---|---|
| Evergreen how-to | Editor | None | High |
| Product tutorial | Editor | Product owner | Medium |
| Competitive page | Editor | Marketing lead | Medium |
| Legal or finance topic | Editor | Subject expert | Low |
| Executive byline | Senior editor | Executive owner | Low |
The point is not bureaucracy. The point is reducing surprise. If everyone knows the lane, work moves faster.
Related reading from our network: AI Publishing Community Building is a useful parallel because community content has the same trust problem: automation helps only when routing and context are preserved.
Escalation and Rollback
Good systems assume mistakes will happen. A published article may include an outdated feature, an unsupported claim, or an unclear recommendation. The workflow should support rollback and correction:
- flag issue
- assign owner
- unpublish or update if needed
- record reason
- notify downstream channel owners
- prevent similar mistakes in future prompts or templates
What breaks in practice is that teams treat publishing as the end. In reality, publishing is just a state transition. Maintenance is part of the system.
Automation That Helps Without Hiding Failure
Webhooks, Queues, and Retries
Automation is useful when it removes repeated handoffs. It is dangerous when it hides failed handoffs.
A strong workflow uses events:
- brief approved
- draft generated
- review requested
- revision requested
- final approved
- publish scheduled
- publish succeeded
- publish failed
These events can trigger notifications, CMS updates, newsletter drafts, or analytics records. But they need queues and retries. CMS APIs fail. Newsletter tools rate-limit requests. Webhooks time out. If the system drops those failures silently, editors lose trust.
Idempotency for Publishing
Idempotency sounds like an engineering detail until the same article publishes twice. Every publish action should have a stable asset ID and target ID. If a retry happens, the system should update or confirm the existing publication, not create a duplicate.
A practical publishing payload includes:
publish_request:
asset_id: post_1842
target: wordpress_blog
action: create_or_update
slug: ai-blog-publishing-software
approved_version: v7
requested_by: editor_03
This keeps automation from becoming chaos. The editor does not need to understand the internals, but the system needs to behave predictably.
Logging for Editors
Logs should not only be for engineers. Editors need readable activity history:
- who changed the title
- when the draft moved to review
- which reviewer requested revisions
- what version was approved
- which CMS publish attempt failed
- which channels received derived versions
If the only audit trail is in developer logs, the workflow is not editorially operational. Editors need enough visibility to manage the calendar without asking engineering to investigate every hiccup.
Measurement: What to Track After Publishing
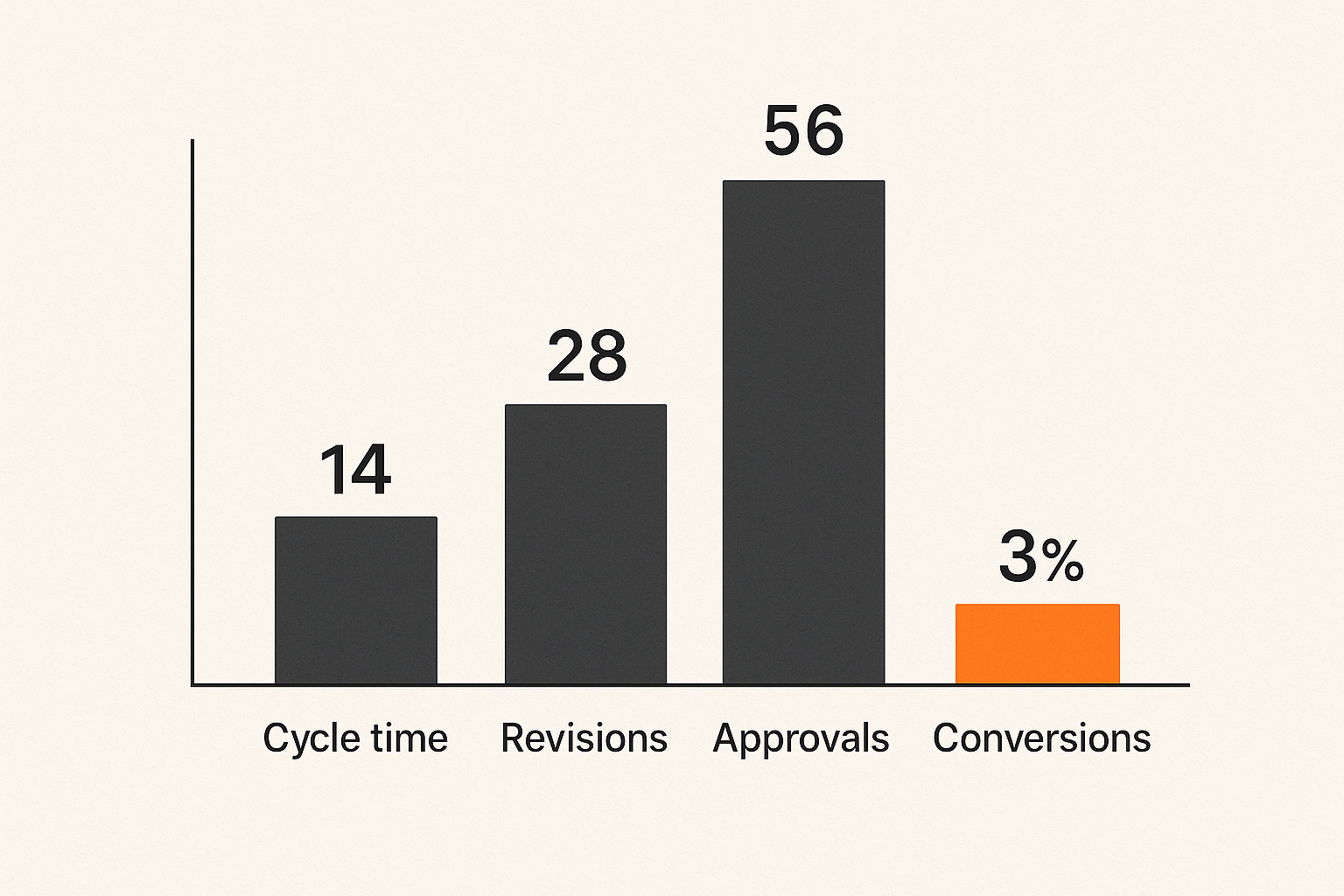
Throughput and Cycle Time
Measurement starts before traffic. A publishing team should know how work moves through the system:
- ideas submitted per week
- briefs approved
- drafts generated
- drafts accepted after first review
- average time from brief to draft
- average time from draft to approval
- average time from approval to publication
These numbers do not need to be perfect at first. They need to reveal where work stalls. If drafts are fast but approvals take three weeks, generation is not the bottleneck.
The same thinking applies to broader AI-generated content operations. The earlier article on AI generated content publishing workflow goes deeper on how review queues, QA, and governance turn generated content into a controlled publishing process.
Quality and Revision Signals
Quality is harder to measure, but revision signals are useful. Track:
- number of revision rounds
- most common reviewer comments
- percentage of drafts rejected
- sources of factual corrections
- brand voice issues by template
- content that required post-publication updates
This creates a feedback loop. If one template causes repeated factual corrections, fix the template. If one persona produces weak intros, improve the brief. If one topic category always needs expert review, route it earlier.
Distribution and Revenue Signals
After publication, track how the asset performs across channels. Blog traffic matters, but so do newsletter clicks, subscriber growth, lead quality, sales enablement usage, community replies, and paid conversion paths.
For teams connecting content to subscriptions, paid products, or gated access, the publishing workflow eventually touches entitlement and payment architecture. Related reading from our network: AI Publishing Cryptocurrency Payment Architecture covers the adjacent problem of connecting AI-scaled content to checkout, webhooks, settlement, and support workflows.
The practical question is not whether every blog post has direct revenue attribution. Many will not. The question is whether the team can see which topics, formats, and channels produce useful outcomes.
What Breaks When Teams Implement It Badly
Draft Piles
The most common failure mode is the draft pile. A team gets excited, generates hundreds of ideas and outlines, then loses track of what is worth editing. The backlog feels like progress, but it is mostly inventory debt.
Draft piles happen when generation is easier than decision-making. The fix is a stricter intake process and a smaller active queue. If an asset has no owner, no target reader, and no publishing destination, it should not be generated yet.
Persona Drift
Persona drift happens when content slowly stops sounding like it was written for a real audience. The writing becomes generic because the system is optimizing for volume, not reader context.
This is especially common when multiple operators use different prompts. One person asks for thought leadership. Another asks for SEO content. Another asks for newsletter copy. Over time, the brand voice fragments.
The fix is shared persona definitions, examples of good and bad output, and review comments that update the system rather than only fixing one draft.
Channel Mismatch
A blog post is not a newsletter. A newsletter is not a social thread. A podcast outline is not a landing page. AI can repurpose content quickly, but repurposing without channel logic creates awkward output.
Channel-specific templates should define length, tone, CTA, formatting, and audience expectation. The system should generate variants from the approved source, not from an unreviewed draft.
No Owner for Exceptions
Every workflow has exceptions: a reviewer is unavailable, a CMS publish fails, a claim needs rechecking, a campaign date changes, or a post underperforms and needs updating.
What breaks in practice is that no one owns the exception. The system says pending, but no one knows who must act. Good AI blog publishing software should make exceptions visible and assignable.
Practical rule: A stalled asset is not a content problem. It is an ownership problem surfaced through content.
Build or Buy: Choosing AI Blog Publishing Software
When Spreadsheets Are Enough
Spreadsheets are fine when the workflow is simple. A solo creator or two-person content team can manage topics, drafts, status, and publish dates with a sheet and a shared editor. There is no shame in that.
Use spreadsheets if:
- monthly volume is low
- one person owns final approval
- few assets need expert review
- publishing happens in one channel
- missed handoffs are rare
- measurement is basic
The mistake is keeping the spreadsheet after the workflow becomes multi-person, multi-channel, and time-sensitive. At that point, the spreadsheet stops being lightweight and becomes a manual database without automation.
When a Platform Is Justified
A platform becomes justified when coordination costs are higher than software costs. That usually happens when you have multiple contributors, recurring publication schedules, persona-specific content, derived assets, approval requirements, or integrations with CMS and newsletter tools.
You do not need enterprise bureaucracy. You need a system that preserves context as work moves from idea to draft to review to publish to measurement.
Comparison Table
| Approach | Works well for | What works | What fails |
|---|---|---|---|
| Prompt plus document editor | Solo creators | Fast drafting, flexible editing | No workflow state, weak audit trail |
| Spreadsheet tracker | Small teams | Simple calendar, visible backlog | Manual handoffs, stale statuses |
| Project management board | Marketing teams | Assignments, due dates, comments | Weak publishing integrations |
| CMS plugin | Blog-only teams | Direct publishing, familiar UI | Limited review routing and variants |
| AI blog publishing software | Multi-channel operators | Generation, review, approval, publishing, measurement | Needs disciplined setup and owners |
The best choice depends on where the bottleneck lives. If drafting is the bottleneck, a simple AI writing tool may help. If review, publishing, and distribution are the bottlenecks, you need workflow software.
Implementation Sequence for Content Teams

A 30-Day Rollout
Do not migrate everything at once. Start with one content lane and prove the workflow.
- Map the current process. List every step from idea to published URL, including informal Slack approvals.
- Choose one repeatable content type. Evergreen SEO posts or newsletter-backed blog posts are good starting points.
- Define required inputs. Create a brief template with audience, intent, sources, CTA, reviewer, and channel.
- Build the state model. Decide which statuses matter and who can move assets between them.
- Configure generation templates. Keep them narrow enough to produce consistent drafts.
- Add review lanes. Route by risk instead of sending everything to everyone.
- Connect publishing targets. Start with one CMS or subdomain before expanding.
- Track cycle time and revision patterns. Use early data to fix templates and routing.
- Expand to variants. Once the blog workflow works, add newsletters, social posts, or podcast outlines.
- Review the system monthly. Remove unused statuses, improve prompts, and tighten ownership.
Roles and Permissions
Roles matter because AI makes it easy for the wrong person to move too quickly. A practical permission model includes:
- contributor: can submit ideas and briefs
- operator: can generate drafts and variants
- editor: can request revisions and approve editorial quality
- subject reviewer: can approve technical or factual sections
- publisher: can schedule and publish approved assets
- admin: can change templates, routing, and integrations
Small teams can combine roles. The point is not hierarchy. The point is preventing accidental publication and preserving review accountability.
What Works and What Fails
What works:
- one clear owner per asset
- small active queue
- reusable briefs
- risk-based review lanes
- visible status
- channel-specific templates
- post-publish measurement
What fails:
- unlimited generation
- vague prompts
- every reviewer on every asset
- no version control
- manual copy-paste publishing
- no exception owner
- measuring only pageviews
The practical question is whether the workflow makes good behavior easier than bad behavior. If the easiest path is to generate, approve, and publish without context, the system will eventually ship weak content.
Where bl0ggers.com Fits
Product Fit
bl0ggers.com is built around the idea that AI publishing needs a human control layer. The product direction is not simply generate more text. It is to help content teams, creators, and publishers turn AI-generated research into publishable assets with review queues, persona journeys, subdomain publishing, podcast and newsletter workflows, and automation hooks.
That matters when a team wants volume but still needs editorial judgment. You can use AI to accelerate research, drafting, repurposing, and formatting while keeping humans in the approval path where the risk is highest.
The product fit is strongest when you have recurring content programs: niche blogs, media networks, newsletters, creator-led publications, topical hubs, or multi-person editorial operations.
Boundaries
No publishing platform fixes strategy by itself. If the audience is unclear, the topics are random, or the team has no point of view, AI will scale the confusion. Software can enforce workflow, preserve context, and shorten handoffs. It cannot decide what your brand should believe.
The healthiest setup is human-led strategy with AI-assisted production and software-enforced workflow. Humans decide the audience, positioning, judgment calls, and final approval. The system handles structure, state, routing, generation, distribution support, and measurement.
Closing Checklist
Before choosing AI blog publishing software, ask:
- What content types are we trying to scale?
- Which steps are slow today?
- Who approves each content type?
- What claims require expert review?
- Which channels need derived versions?
- What systems need integration?
- What states define progress?
- What metrics will tell us the workflow is improving?
If you can answer those questions, the software conversation becomes grounded. If you cannot, start with the workflow map. AI blog publishing software works best when it supports a clear operating model, not when it becomes a substitute for one.
Try bl0ggers.com
bl0ggers.com is for content teams, creators, and publishers who want to use AI to increase output without giving up editorial control. Try bl0ggers.com.