
AI generated content publishing looks easy until the first month of production.
A creator can generate ten drafts in an afternoon. A marketing team can fill a calendar in a day. A publisher can spin up topic clusters, newsletters, and social variants faster than the old editorial process ever allowed.
Then the queue fills up. Drafts conflict with brand voice. Sources need checking. Old claims get repeated. Editors do not know what to review first. Distribution breaks because metadata, canonical URLs, images, and newsletter summaries were treated as afterthoughts.
Teams think the problem is generating more content. The real problem is operating a publishing system where AI, humans, tools, and policies each have a defined role. That changes the conversation. AI generated content publishing is not a prompt trick. It is an architecture decision, a workflow design problem, and a business control system.
Table of contents
- Why ai generated content publishing is an operating system, not a button
- Start with ownership before you automate
- Design the content supply chain
- Build a human-in-the-loop review model
- Quality control for ai generated content publishing
- Automation architecture that does not create chaos
- Distribution, metadata, and channel operations
- Measurement without chasing vanity metrics
- Common failure modes in ai generated content publishing
- Where bl0ggers.com fits in the publishing stack
- Closing the loop on ai generated content publishing
Why ai generated content publishing is an operating system, not a button
Most AI publishing failures start with a reasonable assumption: if generation is faster, publishing should be faster. That is partly true. The draft stage compresses dramatically. But production publishing has more stages than draft creation.
A useful way to think about it is the difference between writing and shipping. Writing produces an asset. Shipping puts that asset into a public system with brand, legal, SEO, trust, support, and commercial consequences.
The output is cheap, the workflow is not
The marginal cost of a draft has fallen. The marginal cost of judgment has not. Someone still has to decide whether the piece is accurate, useful, differentiated, on-brand, properly routed, and worth publishing.
The mistake teams make is pricing AI generated content publishing around draft volume. In practice, the bottleneck moves to intake, review, approval, formatting, metadata, internal linking, distribution, and post-publication maintenance.
Practical rule: Treat every generated article as an item moving through a production pipeline, not as a file waiting for a copy edit.
Publishing risk moves downstream
When a human writes slowly, many mistakes are caught during creation. When AI drafts quickly, problems often surface after generation. That includes weak claims, duplicate angles, outdated assumptions, invented details, shallow examples, and missing context.
This does not mean AI content is unusable. It means risk has moved. Your workflow must catch issues after generation but before publication, and it must do that without turning every article into a committee project.
The practical question for 2026
The practical question is not whether AI can create publishable content. It can. The practical question is whether your team can run a repeatable system that decides what to generate, what to review, what to reject, what to publish, and what to update later.
Related reading from our network: teams using publishing systems for local coordination face similar trust and routing problems in AI publishing community building, where the content is only useful if it triggers the right follow-up.
Start with ownership before you automate
Automation without ownership creates faster confusion. Before prompts, templates, and webhooks, decide who owns the content system.
Assign the content owner
Every publishing program needs a responsible owner. Not a vague shared channel. Not a rotating whoever has time. One owner should be accountable for the quality bar, taxonomy, publishing cadence, and escalation path.
For a solo creator, that owner is obvious. For a marketing team, it may be the content lead. For a publisher, it may be a managing editor or content operations manager.
The owner does not need to touch every article. They need to own the system.
Separate operator, editor, and approver roles
AI generated content publishing works better when roles are separated:
| Role | Primary job | Should not be responsible for |
|---|---|---|
| Operator | Runs prompts, imports briefs, manages queues | Final brand or legal approval |
| Editor | Improves structure, voice, accuracy, usefulness | Building automation logic |
| Approver | Accepts risk and authorizes publishing | Cleaning every paragraph |
| Analyst | Measures performance and decay | Deciding editorial policy alone |
Small teams can combine roles, but they should not confuse them. If one person does everything, the workflow should still name which hat they are wearing at each step.
Make escalation visible
What breaks in practice is the gray zone. An editor sees a claim that may need expert review. A generated article mentions a competitor. A topic touches finance, health, law, or security. Nobody knows whether to publish, rewrite, or escalate.
Create explicit escalation labels:
- factual uncertainty
- brand risk
- legal sensitivity
- customer impact
- low confidence source material
- duplicate topic conflict
- outdated claim
Practical rule: If a reviewer cannot escalate in one click or one field, they will either block too much content or publish too much risk.
Design the content supply chain
AI content systems are supply chains. Inputs come in, drafts are transformed, assets are enriched, humans inspect them, and finished content is distributed.
Inputs decide quality
Bad inputs produce expensive review work. Good inputs reduce editing time before the model writes a word.
Useful inputs include:
- audience segment
- search intent or reader job
- brand point of view
- source material
- examples or product context
- excluded claims
- internal links to consider
- desired format
- review level
A thin prompt like write a blog post about onboarding gives you a generic draft. A structured brief gives you a production asset.
Use stages, not a single draft folder
A single folder called drafts does not scale. You need status states that tell operators what should happen next.
A workable stage model:
- Idea captured
- Brief approved
- AI draft generated
- Editorial review
- Expert or risk review if needed
- SEO and metadata pass
- Final approval
- Scheduled or published
- Performance monitoring
- Refresh or retire
This is where many teams benefit from formalizing a human-in-the-loop AI publishing workflow instead of relying on chat threads, docs, and memory.
Track state like a product team
Content teams often under-track state. Product and engineering teams usually know whether a ticket is blocked, in review, approved, shipped, or rolled back. Publishing teams need the same discipline.
A simple content item record might include:
content_id: ai-pub-042
persona: indie_creator
topic_cluster: content_operations
status: editorial_review
risk_level: medium
owner: content_lead
reviewer: editor_01
source_pack: approved
canonical_url: pending
publish_target: blog
newsletter_variant: required
last_updated: 2026-05-30
This is not bureaucracy. It is how you keep AI volume from overwhelming human oversight.
Build a human-in-the-loop review model
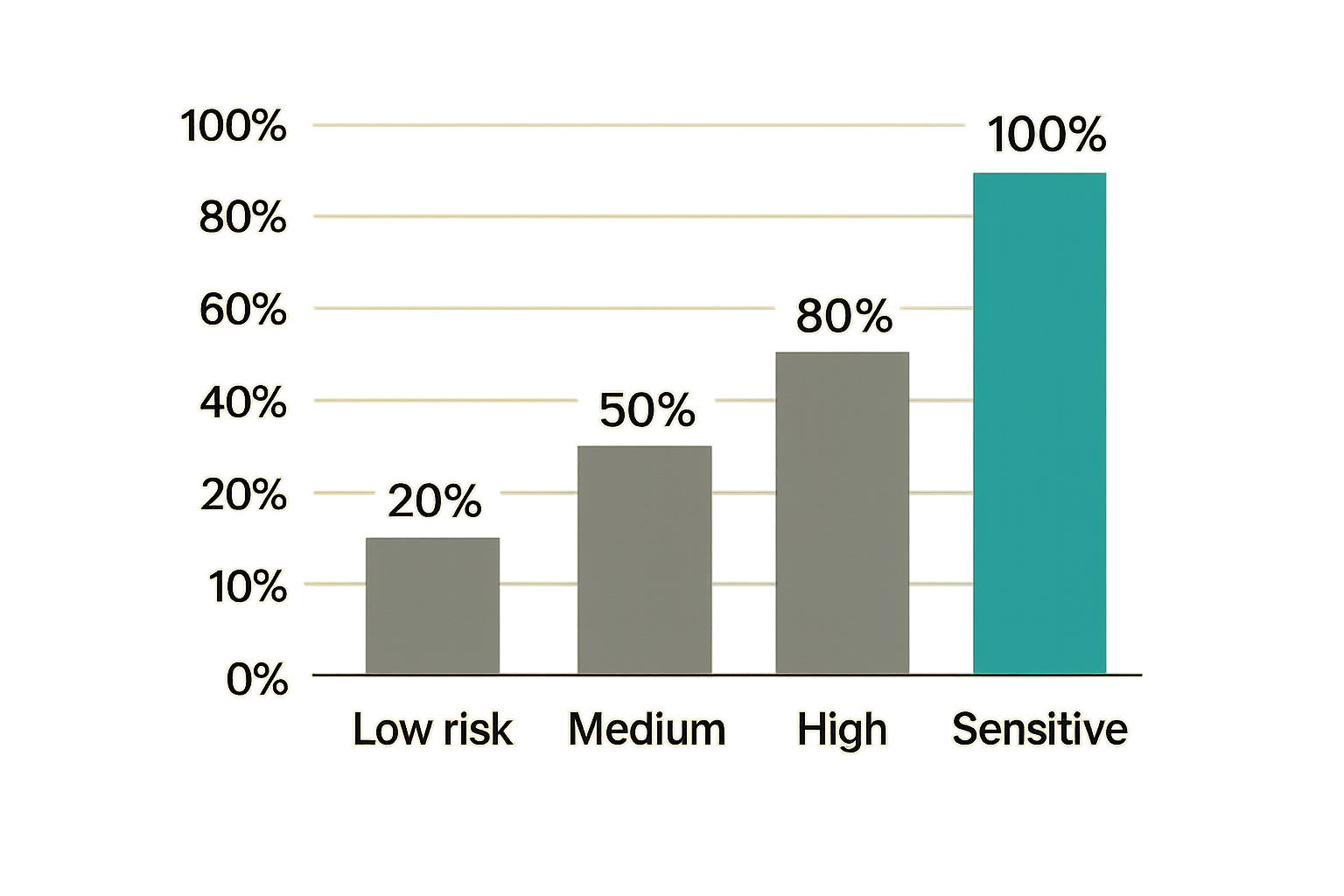
Human review is not a moral decoration added to AI. It is a routing system. The goal is to put the right human judgment on the right content at the right time.
Review by risk, not ego
Not every article deserves the same review depth. A low-risk tutorial for an internal newsletter may need a light editorial pass. A thought leadership article making claims about customer results needs heavier review.
Use a risk model:
| Content type | Example | Review depth |
|---|---|---|
| Low risk | Glossary, simple how-to, recap | Editorial QA |
| Medium risk | Product comparison, SEO article, opinion piece | Editor plus owner approval |
| High risk | Legal, medical, financial, security, public claims | Expert review plus approver |
| Sensitive | Crisis response, customer-specific content | Manual workflow only |
This keeps humans focused where judgment matters most.
Create review queues that match expertise
A useful review queue does not just say needs review. It says who should review and why.
Queues can be organized by:
- topic expertise
- brand sensitivity
- funnel stage
- publication channel
- persona
- legal or compliance risk
- customer impact
For broader operating design, the companion piece on the human-in-the-loop AI publishing operating model goes deeper on ownership, routing, and governance.
Do not approve what you cannot audit
Approval should leave a trail. You should know who approved a piece, what changed after generation, what sources were used, and why the piece was published.
This matters when performance drops, a claim is challenged, or a team member leaves. Without auditability, you cannot improve the system. You can only argue about individual articles.
Practical rule: Human approval is only operationally meaningful if it is attached to version history, reviewer identity, and publication state.
Quality control for ai generated content publishing
Quality control is where AI generated content publishing becomes durable. Without QA, the system slowly drifts toward sameness, repetition, and preventable mistakes.
What works
What works is a layered QA model:
- brief validation before generation
- source checks during review
- structural editing for clarity
- brand voice pass
- fact and claim verification
- metadata and link review
- duplicate topic detection
- post-publication monitoring
The best teams do not rely on one heroic editor. They build small controls into each stage.
What fails
What fails is treating quality as vibe. If feedback is only this feels off, the system cannot learn.
Common weak QA patterns include:
- no definition of publishable
- no source requirements
- no rejected-content log
- no reviewer notes
- no distinction between style edits and factual corrections
- no update schedule
- no owner for stale content
Related reading from our network: security teams have a similar problem when they confuse policy with workflow; AI publishing threat detection as a SOC workflow is a useful adjacent lens for thinking about signals, alerts, validation, and response.
A lightweight QA checklist
A practical QA checklist should be short enough to use and specific enough to matter:
- Does the article answer a real reader job?
- Are claims supported by approved source material?
- Is the point of view distinct from generic web content?
- Are examples concrete and relevant to the audience?
- Are internal links useful rather than decorative?
- Is metadata complete?
- Is the article assigned to an owner for future updates?
If the checklist becomes a 90-field form, people will route around it. Keep the first version lean.
Automation architecture that does not create chaos
Automation should remove repeated handoffs, not remove judgment. The architecture should be explicit about where machines act, where humans decide, and where the system waits.
Use events instead of manual handoffs
A publishing workflow should be event-driven where possible. When a brief is approved, generate a draft. When a draft is generated, create a review task. When review is approved, prepare metadata. When final approval happens, schedule publication.
That does not mean everything publishes automatically. It means the system moves work to the next responsible place without relying on someone to remember.
Idempotency matters in publishing too
Payment and infrastructure teams talk about idempotency because retries can create duplicate charges or duplicate actions. Publishing has the same class of problem.
A failed webhook should not publish the same article twice. A retry should not create three newsletter drafts. A CMS sync should not overwrite human edits with an older generated version.
Design with stable content IDs, version numbers, and safe retry logic.
event: editorial_approved
content_id: ai-pub-042
version: 7
action: prepare_publish_package
idempotency_key: ai-pub-042-v7-publish-package
retry_policy: safe_if_no_newer_version
A practical implementation sequence
Start small and make state visible before adding more automation.
- Define content types and risk levels.
- Create structured briefs for each content type.
- Build a draft generation step from approved briefs.
- Route drafts into review queues by risk and topic.
- Add QA fields for claims, links, metadata, and owner approval.
- Create publish packages for CMS, newsletter, and social channels.
- Add webhooks or API sync only after states are reliable.
- Measure cycle time, rejection reasons, and update needs.
Related reading from our network: content businesses that monetize with digital payments face the same state and retry issues; AI publishing cryptocurrency payment architecture frames checkout, webhooks, entitlements, and support as workflow problems rather than UI problems.
Distribution, metadata, and channel operations

The UI is not the whole publishing system. The CMS editor is only where one version of the content lands. The operational work includes metadata, channel variants, indexing, updates, and support context.
The CMS is only one endpoint
A single article may produce:
- a blog post
- newsletter summary
- podcast script
- short social posts
- internal sales note
- community discussion prompt
- search snippet
- content refresh task
If these are generated manually after publication, teams lose the speed they gained from AI. If they are generated automatically without review, teams create inconsistency. The better pattern is to create a publish package that contains approved variants and channel-specific metadata.
Metadata is operational infrastructure
Metadata is not an SEO afterthought. It controls routing, measurement, ownership, and refresh cycles.
Useful metadata includes:
| Field | Why it matters |
|---|---|
| Persona | Keeps content tied to a target reader |
| Topic cluster | Prevents duplication and supports internal linking |
| Risk level | Determines review depth |
| Source pack | Shows what the article is allowed to rely on |
| Owner | Assigns accountability after publication |
| Refresh date | Prevents content decay |
| Channel targets | Supports repurposing without chaos |
Plan for updates and decay
AI makes it easy to publish. It does not make old content stay accurate. In fast-moving topics, decay is a normal operating condition.
Build update triggers:
- traffic drops
- conversion drops
- product feature changes
- regulatory changes
- broken links
- search intent shifts
- support team flags
- competitor or market changes
What breaks in practice is nobody owns old AI-assisted content. The archive grows, trust erodes, and the team keeps generating new articles instead of maintaining useful ones.
Measurement without chasing vanity metrics
A publishing system should produce measurable flow and business outcomes. Pageviews matter, but they are not enough.
Measure flow, not only traffic
Track operational metrics such as:
- idea-to-brief time
- brief approval rate
- draft-to-review time
- review cycle time
- rejection reasons
- approval rate by content type
- publish frequency by persona
- refresh backlog
These metrics tell you whether the machine is healthy. A traffic spike can hide a broken workflow. A steady queue with high approval quality is usually more valuable than chaotic volume.
Connect editorial data to business data
For marketing teams, connect content to leads, trials, demos, customer education, and retention. For creators, connect it to subscribers, product sales, community growth, and audience feedback. For publishers, connect it to session quality, newsletter growth, ad yield, and topic authority.
This does not require perfect attribution. It requires enough signal to stop publishing blindly.
Use feedback to tune the system
Feedback should improve prompts, briefs, review rules, and topic selection. If editors keep making the same correction, fix the brief. If articles in one cluster keep underperforming, revisit intent. If a model keeps producing vague examples, add concrete source material.
Practical rule: Do not use human edits only to fix articles. Use them to fix the system that produced the articles.
Common failure modes in ai generated content publishing
Most failures are not dramatic. They are slow operational leaks.
The content farm trap
The content farm trap starts with volume goals and ends with undifferentiated pages. The team measures output instead of usefulness. Prompts get reused. Articles sound interchangeable. Internal links are inserted mechanically. Readers leave quickly.
The fix is to require a point of view, a reader job, and a reason to publish before generation.
The invisible editor problem
Many teams claim to have human review, but the editor has no time, authority, or context. They skim drafts after the strategy has already been decided. They are expected to make weak articles acceptable instead of rejecting them.
Human review has to include the ability to send content backward, escalate risk, and block publication.
The integration gap
The integration gap appears when the AI tool, CMS, newsletter platform, analytics tool, and task manager do not share state. A draft is approved in one place but still marked pending elsewhere. A published article has no refresh owner. A newsletter variant uses an old title.
This is why AI generated content publishing should be designed as a workflow across systems, not as a collection of disconnected tools.
Where bl0ggers.com fits in the publishing stack
For creators and publishers, the platform question should come after the workflow question. If your workflow is unclear, software will automate the mess. If your workflow is clear, a platform can remove a lot of manual coordination.
Persona-led publishing at scale
bl0ggers.com is built around the idea that AI-assisted publishing should be persona-led. That matters because generic content is rarely the goal. Creators, marketing teams, and indie publishers usually serve specific audiences with specific pain points.
A persona-led system keeps briefs, drafts, channels, and review rules tied to the reader instead of treating every article as a standalone output.
Review queues and automation boundaries
The useful boundary is not AI versus human. The useful boundary is automated where repeatable, reviewed where judgment matters.
That means AI can help with research synthesis, outline generation, draft creation, summaries, variants, and metadata. Humans should retain control over claims, positioning, approvals, sensitive topics, and final publishing rules.
When a platform is the right move
A platform becomes useful when the content operation has enough moving parts that docs and spreadsheets start to break. Signs include:
- multiple personas or sites
- recurring article generation
- review queues across contributors
- newsletters or podcasts from the same research base
- subdomain publishing needs
- webhook-based automation
- a need for human oversight without slowing every item
This is the area where bl0ggers.com is designed to help: scaling AI-assisted blogs, newsletters, podcasts, and publishing workflows while keeping review and ownership visible.
Closing the loop on ai generated content publishing
AI generated content publishing is not a shortcut around editorial responsibility. It is a way to redesign the publishing workflow so humans spend less time on blank-page production and more time on judgment, positioning, quality, and distribution.
The operator standard
The operator standard is simple:
- every article has a reason to exist
- every draft has structured inputs
- every review has an owner
- every approval is auditable
- every publish action has state
- every channel variant is intentional
- every old article has a maintenance path
If you can do that, AI becomes leverage. If you cannot, AI becomes a faster way to create cleanup work.
The teams that win with ai generated content publishing in 2026 will not be the teams that generate the most drafts. They will be the teams that build the cleanest workflow from idea to update.
Try bl0ggers.com
bl0ggers.com helps creators and publishers use AI to scale content production while maintaining human oversight across blogs, newsletters, podcasts, review queues, and publishing automation.