AI generated content publishing sounds simple until the calendar fills up, drafts multiply, and nobody knows which piece is approved, which one needs expert review, and which one was already sent to the newsletter queue.
Teams think the problem is content generation. The real problem is publishing control.
A model can create a draft in seconds. It cannot automatically know your editorial risk tolerance, brand exceptions, legal boundaries, audience promises, distribution plan, or support load. That changes the conversation. The practical question is not whether AI can write. It is whether your team can operate an AI-assisted publishing system without losing track of quality, ownership, and trust.
In 2026, ai generated content publishing is no longer a side experiment for most serious content teams. It is becoming part of the production stack. The mistake teams make is treating it like a prompt library. A useful way to think about it is as an architecture problem: inputs, states, review lanes, approvals, publishing targets, feedback, and measurement.
Table of contents
- AI Generated Content Publishing Is an Operating System, Not a Prompting Trick
- Start With the Editorial State Machine
- Design Review Lanes Before You Increase Volume
- Build the Content Brief as the Source of Truth
- Connect Generation to Approval, Not Direct Publishing
- Measure the Bottlenecks That Actually Matter
- Common Failure Modes in AI Generated Content Publishing
- What Works and What Fails in Production
- Distribution, Repurposing, and Feedback Loops
- Where bl0ggers.com Fits in the Workflow
AI Generated Content Publishing Is an Operating System, Not a Prompting Trick

Output is not throughput
The first win from AI is obvious: drafts arrive faster. That is useful, but it is not the same as publishing throughput.
Throughput means a qualified idea becomes a finished asset, passes review, reaches the right channel, and produces a measurable result. If generation gets faster but review, approval, and distribution stay chaotic, the team does not scale. It just creates a larger backlog.
What breaks in practice is usually not the model. It is the queue around the model. A content lead asks for ten drafts. The AI produces them. Then editors spend two days figuring out which drafts are worth saving, which claims need checking, which pieces overlap, and which ones have no clear buyer journey. The visible cost moved from writing to triage.
Practical rule: Treat AI output as inventory, not finished goods. Inventory still needs inspection, packaging, routing, and release control.
This is why ai generated content publishing must be designed as a production workflow. If you only optimize prompt quality, you miss the operational layer where most publishing teams actually lose time.
The control plane matters
Every scalable system needs a control plane. In publishing, that means a place where the team can see what is being created, why it exists, who owns the next decision, and what is allowed to happen next.
For AI-assisted content, the control plane should answer five questions:
- What brief, persona, and objective produced this draft?
- What risk level does the content carry?
- Which review lane does it belong in?
- What edits or approvals are still required?
- Where will it publish, repurpose, or syndicate?
Without that layer, teams rely on Slack threads, spreadsheet notes, CMS drafts, and memory. That works for five posts. It fails when you add newsletters, podcasts, social cuts, partner pages, and multiple personas.
The mistake teams make is asking, Which model should we use? too early. The better first question is: what publishing state should each AI-generated asset move through before it reaches an audience?
Start With the Editorial State Machine
Define states before tools
A state machine sounds formal, but the idea is simple. Content should move through named states with clear entry and exit criteria. If nobody can explain the states, nobody can manage the workflow.
A practical AI publishing state model might look like this:
- Idea captured
- Brief approved
- AI draft generated
- Editorial triage complete
- Subject matter review required or skipped
- Fact and claim check complete
- Final editor approval
- Scheduled or published
- Performance reviewed
- Brief updated based on learning
The exact states depend on your business. A newsletter operator may need sponsor approval. A healthcare publisher may need compliance review. A creator selling courses may need offer alignment. The point is not to copy someone else’s board. The point is to make the invisible decisions visible.
A useful way to think about it is that AI does not remove workflow states. It changes the volume and timing of work inside them.
Make handoffs visible
Handoffs are where AI publishing systems usually leak quality. A writer assumes the editor checked citations. The editor assumes the subject matter expert validated the technical claim. The marketing lead assumes the draft is ready for email. The CMS owner assumes the headline is final.
That ambiguity creates rework and trust issues.
Each handoff should include:
- Current state
- Next owner
- Required decision
- Known risks or unresolved questions
- Due date or service level expectation
This does not require enterprise software. It requires discipline. Even a simple review queue can work if the states and owners are explicit. The difference is that AI increases the number of handoffs. You cannot manage that with casual coordination for long.
For a deeper adjacent architecture, the prior bl0ggers.com guide to human-in-the-loop AI publishing workflow architecture is useful because it treats review routing and editorial control as the core system, not a cleanup step.
Design Review Lanes Before You Increase Volume
Route by risk, not by ego
Not every asset deserves the same review path. One of the fastest ways to stall an AI publishing program is to make every draft wait for the most senior editor.
Review should be risk-based.
Low-risk assets might include glossary pages, internal summaries, social variations, or repurposed newsletter snippets. Medium-risk assets might include SEO posts, comparison articles, and product education. High-risk assets might include legal topics, financial claims, medical guidance, security advice, pricing pages, and anything that could create customer support obligations.
The practical question is: what can be safely reviewed by an editor, and what must be escalated to a domain owner?
A simple review lane table helps:
| Content type | Risk level | Required review | Automation allowed |
|---|---|---|---|
| Social variations | Low | Editorial scan | Generate, queue, format |
| SEO explainer | Medium | Editor plus claim check | Draft, outline, metadata |
| Product comparison | Medium | Editor plus product owner | Draft, table, internal links |
| Legal or finance guide | High | Expert review required | Research assist only |
| Customer-facing policy | High | Legal or leadership approval | No direct publish |
Practical rule: Review lanes should be based on downside risk, not on how impressive or polished the draft looks.
AI output often sounds confident. That is not the same as being correct, current, or appropriate for your audience. Polished wrongness is more dangerous than an obvious rough draft because it moves faster through weak review systems.
Use quality gates as decision points
A quality gate is not a proofreading checklist. It is a decision point where content either moves forward, loops back, or gets killed.
Good gates are specific:
- Does the article answer the search intent promised by the brief?
- Are claims supported by approved sources or internal knowledge?
- Is the point of view distinct from generic model output?
- Is the CTA appropriate for the reader stage?
- Are internal links relevant, not decorative?
- Does the draft create support, legal, or brand risk?
Bad gates are vague:
- Make it better
- Sound more human
- Add more value
- Fix the AI feel
Those comments may be emotionally accurate, but they are operationally weak. They do not tell the system what to change next time.
Related reading from our network: teams applying AI to security content face a similar routing problem where outputs must connect to identity, alerts, validation, and incident response, as outlined in AI publishing threat detection as a SOC workflow.
Build the Content Brief as the Source of Truth
Inputs beat clever prompts
Most teams over-invest in prompts and under-invest in briefs. The prompt matters, but the brief is where editorial intent lives.
A strong AI publishing brief should include:
- Audience segment
- Search or audience intent
- Content job to be done
- Primary angle
- Required points of view
- Claims to include or avoid
- Competitors or references to differentiate from
- Internal links to consider
- CTA and funnel stage
- Review lane and risk level
- Distribution plan
If the brief is weak, the model fills gaps with generic assumptions. That is how you get articles that are technically readable but strategically useless.
Here is a compact brief format many teams can adapt:
asset_type: blog_post
persona: newsletter_operator
intent: learn how to scale publishing with AI without losing trust
primary_keyword: ai generated content publishing
angle: workflow architecture, not prompt tactics
risk_level: medium
required_review: editor
must_include:
- review lanes
- quality gates
- approval states
- distribution feedback
avoid:
- unsupported statistics
- generic AI hype
cta_stage: product-aware
The brief becomes the contract between strategy, generation, review, and distribution. If you treat it as optional, every downstream step becomes subjective.
Reusable constraints keep the system stable
AI publishing systems need reusable constraints. Otherwise every draft becomes a one-off negotiation.
Common constraints include:
- Brand voice rules
- Forbidden claims
- Approved terminology
- Link policy
- Citation expectations
- Disclosure rules
- Competitive positioning
- Formatting standards
- CTA rules by funnel stage
These constraints should not live only in a style guide PDF nobody opens. They need to be available at generation time and review time.
What works is boring: documented rules, reusable templates, and structured metadata. What fails is expecting editors to remember every exception while reviewing a flood of drafts.
Connect Generation to Approval, Not Direct Publishing
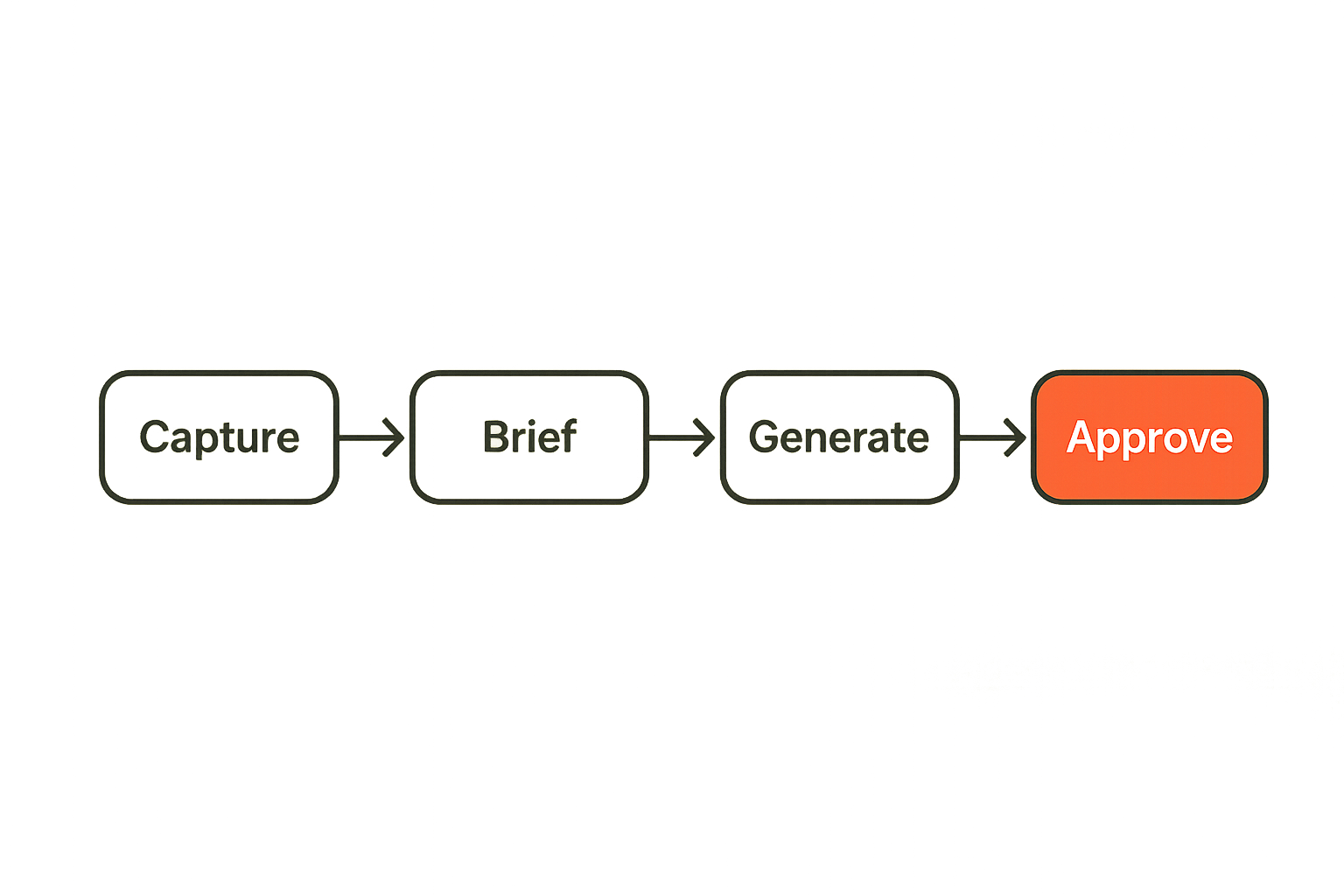
A practical implementation sequence
Direct-to-publish automation is tempting. It is also where many teams damage trust.
The safer pattern is generation to approval. Automation prepares the work. Humans approve the release path based on risk.
A practical implementation sequence looks like this:
- Capture ideas from search, customer questions, sales calls, community discussions, and editorial planning.
- Convert approved ideas into structured briefs with persona, angle, risk level, CTA, and distribution plan.
- Generate outlines first, not full drafts, for medium and high-risk content.
- Review the outline for intent, originality, and coverage before drafting.
- Generate the draft with the approved brief and constraints attached.
- Run automated checks for duplication, missing sections, forbidden claims, metadata, and formatting.
- Route the draft to the correct review lane based on risk.
- Approve, revise, or reject with reasons captured as structured feedback.
- Publish to the CMS, newsletter, or other channel only after final approval.
- Feed performance and editorial notes back into future briefs.
This sequence slows down the wrong things and speeds up the right things. You reduce manual blank-page work while preserving release control.
Practical rule: Automate preparation, formatting, routing, and reminders before you automate final publishing decisions.
What automation should not own
Automation should not own editorial judgment. It can assist judgment, but it should not silently replace it.
Be careful with automation around:
- Legal conclusions
- Financial advice
- Medical recommendations
- Security guidance
- Product promises
- Pricing or policy language
- Sensitive community topics
- Claims about competitors
This does not mean AI cannot help with these topics. It means the workflow must mark them as high-risk and route them accordingly.
The same principle applies to monetization and access control. If your AI-assisted content business includes paid newsletters, gated research, or crypto payments, checkout state and entitlement logic matter as much as publishing state. Related reading from our network: AI publishing cryptocurrency payment architecture covers the payment-side version of the same workflow problem.
Measure the Bottlenecks That Actually Matter
Track flow, rework, and outcomes
If you only measure how many drafts AI produced, you will optimize the wrong thing.
Better operational metrics include:
- Time from idea to approved brief
- Time from brief to first draft
- Time in editorial review
- Percentage of drafts returned for major revision
- Percentage of drafts killed after generation
- Number of review cycles per asset
- Time from approval to publish
- Performance by brief type or persona
- Content updates triggered by feedback
These metrics show where the system is actually constrained. If draft time drops from four hours to four minutes but review time grows from one day to six days, your bottleneck moved. That is not failure, but it changes what you should fix next.
A good publishing dashboard separates generation velocity from approval velocity. Otherwise leadership sees a big output number while editors experience a collapsing queue.
Avoid vanity publishing metrics
Vanity metrics are especially dangerous in AI generated content publishing because volume is easy to inflate.
Weak metrics include:
- Number of AI drafts created
- Total words generated
- Number of prompts run
- Number of posts scheduled without quality context
- Raw traffic without intent or conversion quality
These metrics can be useful as diagnostics, but they should not define success. The goal is not more text. The goal is more useful, trusted, strategically aligned publishing.
What works is connecting operational metrics to business outcomes. For example, a publisher might track which AI-assisted briefs lead to newsletter signups, which topics increase return visits, and which formats create support tickets. That is a healthier system than celebrating a content calendar that doubled while engagement fell.
Common Failure Modes in AI Generated Content Publishing
Voice drift and duplicated thinking
The most common failure mode is not obvious hallucination. It is voice drift.
At first, AI drafts look fine. Then the site slowly starts sounding like every other site in the category. Introductions use the same patterns. Advice becomes broad. Contrarian positions soften. Examples become generic. The content still passes grammar checks, but the brand loses its edge.
This happens when teams use AI as the source of thinking instead of the drafting layer around human editorial judgment.
The fix is to preserve human inputs where they matter:
- Founder point of view
- Customer objections
- Original frameworks
- Internal data or observations
- Strong editorial stance
- Examples from real operations
Duplicated thinking is another quiet problem. Multiple AI drafts may cover the same idea with different headlines. Without a topic map, teams publish overlapping assets that compete with each other and confuse readers.
A topic map should define canonical pages, supporting posts, update schedules, and internal link relationships. AI can help maintain it, but editorial strategy must own it.
Compliance, trust, and support debt
Bad AI publishing creates debt outside the content team.
Support teams get questions about promises the article implied. Sales teams get prospects referencing outdated claims. Product teams get asked about features that do not exist. Legal teams discover risky language after it is already indexed.
That is why content risk is business risk.
The mistake teams make is reviewing AI content only for readability. Readability is the lowest bar. A piece can be readable and still be wrong for the business.
High-risk content should trigger additional checks:
- Is this claim still true today?
- Would support agree with this wording?
- Does product positioning match the roadmap?
- Are limitations clearly explained?
- Is the reader likely to make a costly decision based on this?
Related reading from our network: community publishers face a trust version of this same problem, where AI content must support coordination rather than create noise; see AI publishing community building.
What Works and What Fails in Production
A comparison for operators
The difference between a workable AI publishing system and a messy one is usually visible in the operating model.
| Area | What fails | What works |
|---|---|---|
| Planning | Random prompts from scattered ideas | Approved briefs tied to personas and goals |
| Generation | Full drafts created before intent is validated | Outlines reviewed before high-effort drafting |
| Review | Everyone reviews everything or nobody owns review | Risk-based lanes with named owners |
| Quality | Vague comments like make it better | Specific gates with pass, revise, reject decisions |
| Publishing | AI drafts pushed straight into CMS | Approval state required before release |
| Measurement | Counting words, drafts, and posts | Tracking cycle time, rework, and outcomes |
| Learning | Editors fix the same issues repeatedly | Feedback updates templates, constraints, and briefs |
What breaks in practice is not a lack of enthusiasm. It is lack of separation between draft creation and publishing authority.
When those are separate, AI can accelerate the parts it is good at: outlines, variants, summaries, metadata, repurposing, and first drafts. Humans keep control over point of view, risk, final judgment, and audience trust.
Practical rules for implementation
If you are building this inside a real team, keep the rules blunt.
Practical rule: No brief, no generation. If an idea is not clear enough to brief, it is not ready for AI-assisted production.
Practical rule: No risk label, no routing. Every asset should declare whether it is low, medium, or high risk before review begins.
Practical rule: No approval state, no publishing. A draft in the CMS is not the same as an approved asset.
These rules sound restrictive, but they actually make the system faster. Editors spend less time guessing. Writers spend less time defending drafts. Operators can see bottlenecks. Leadership gets a realistic view of capacity.
The practical question is not how to remove humans. It is where human judgment creates the most leverage.
Usually, the answer is upstream and downstream: better briefs before generation, sharper review after generation, and smarter learning after publication.
Distribution, Repurposing, and Feedback Loops
Package once, adapt per channel
Publishing does not end when the blog post goes live. For many teams, the blog is only the source asset.
A strong AI generated content publishing workflow should define distribution packages at the brief stage. One approved article might produce:
- Newsletter edition
- LinkedIn post
- Short-form social thread
- Podcast outline
- Sales enablement summary
- Community discussion prompt
- Internal knowledge base note
The mistake teams make is repurposing after the fact with no channel logic. A newsletter is not a shortened blog post. A podcast outline is not a list of headings. A social post is not a random excerpt.
Each channel needs its own job.
For example, the blog post may capture search demand. The newsletter may add a sharper operator note. The social post may test a single argument. The podcast outline may turn the topic into a conversation. AI can help create these variations, but the distribution strategy should define what each one is supposed to do.
Feed learning back into the brief
The feedback loop is where AI publishing gets better or gets noisy.
Useful feedback includes:
- Which briefs produced strong engagement
- Which topics attracted the wrong audience
- Which claims required correction
- Which reviewer comments repeated across drafts
- Which CTAs matched reader intent
- Which channels performed for each persona
This feedback should update future briefs, templates, and constraints. If reviewers keep fixing the same introduction pattern, change the prompt or template. If product reviewers keep flagging the same claim, add it to forbidden language. If certain topics create support confusion, update the risk label.
A publishing system that does not learn becomes a content factory with recurring defects.
A publishing system that learns becomes an editorial engine. That is the difference between using AI to produce more and using AI to operate better.
Where bl0ggers.com Fits in the Workflow
Product fit without replacing editors
bl0ggers.com is built around a simple premise: AI can increase publishing output, but editorial control still needs an operating model.
That means the useful product surface is not just generation. It is the workflow around generation: persona-led articles, review queues, optional human review, podcasts, newsletters, subdomain publishing, and automation hooks. Teams that want to understand the platform direction can read more about bl0ggers.com as a human-in-the-loop AI publishing platform.
The fit is strongest when a team already knows it needs more output but does not want a blind auto-publishing machine. That includes content marketers managing SEO programs, newsletter operators turning recurring topics into editions, creators building media libraries, and publishers coordinating multiple sub-brands or personas.
The goal is not to replace editors. The goal is to give editors a better control surface: clearer inputs, faster draft creation, structured review, and cleaner handoff into distribution.
Start with one controlled publishing lane
Do not start by automating the entire content operation.
Start with one lane:
- One audience persona
- One asset type
- One review path
- One publishing destination
- One measurement loop
For example, a B2B content team might start with medium-risk SEO articles for a single product category. A creator might start with weekly newsletter-to-blog repurposing. A publisher might start with local topic summaries that require editor approval before going live.
Define the brief. Generate outlines. Review the first few manually. Add quality gates. Track rework. Only then expand to more topics, personas, or channels.
Teams that want to test a controlled lane can create a bl0ggers.com account and set up a workflow around generated articles, review, and publishing destinations rather than treating AI output as a loose document dump.
The closing point is simple: ai generated content publishing works when it is designed as a workflow. It fails when it is treated as a shortcut around editorial responsibility.
Try bl0ggers.com
bl0ggers.com is for content teams, creators, and publishers who want to use AI to increase output without giving up editorial control. Try bl0ggers.com.