
Cloud computing AI content sounds like a tooling decision. Pick a model, connect a writing app, ask for drafts, publish more often.
That is where many teams start to lose control.
The pain shows up later: five versions of the same article in different docs, unclear ownership of AI edits, inconsistent brand voice, legal review happening too late, newsletter copy that does not match the blog, and performance data that never makes it back into the next brief.
Teams think the problem is AI content quality. The real problem is publishing architecture. Cloud computing gives content teams elastic compute, shared storage, APIs, and automation. AI gives them generation, summarization, classification, and transformation. But neither one creates a reliable editorial operation by default.
The practical question is not, can we use AI to write more? The practical question is, can we design a cloud-based content system where AI speeds up production without removing human judgment from the places where judgment matters?
Table of contents
- Cloud computing AI content is an operating model
- The stack behind cloud computing AI content
- Human in the loop is the control layer
- Designing the AI content workflow
- Quality gates for cloud computing AI content
- What breaks when implementation is loose
- Cost performance and governance in the cloud
- A practical implementation sequence
- What works and what fails
- Where bl0ggers.com fits in the cloud computing AI content workflow
Cloud computing AI content is an operating model
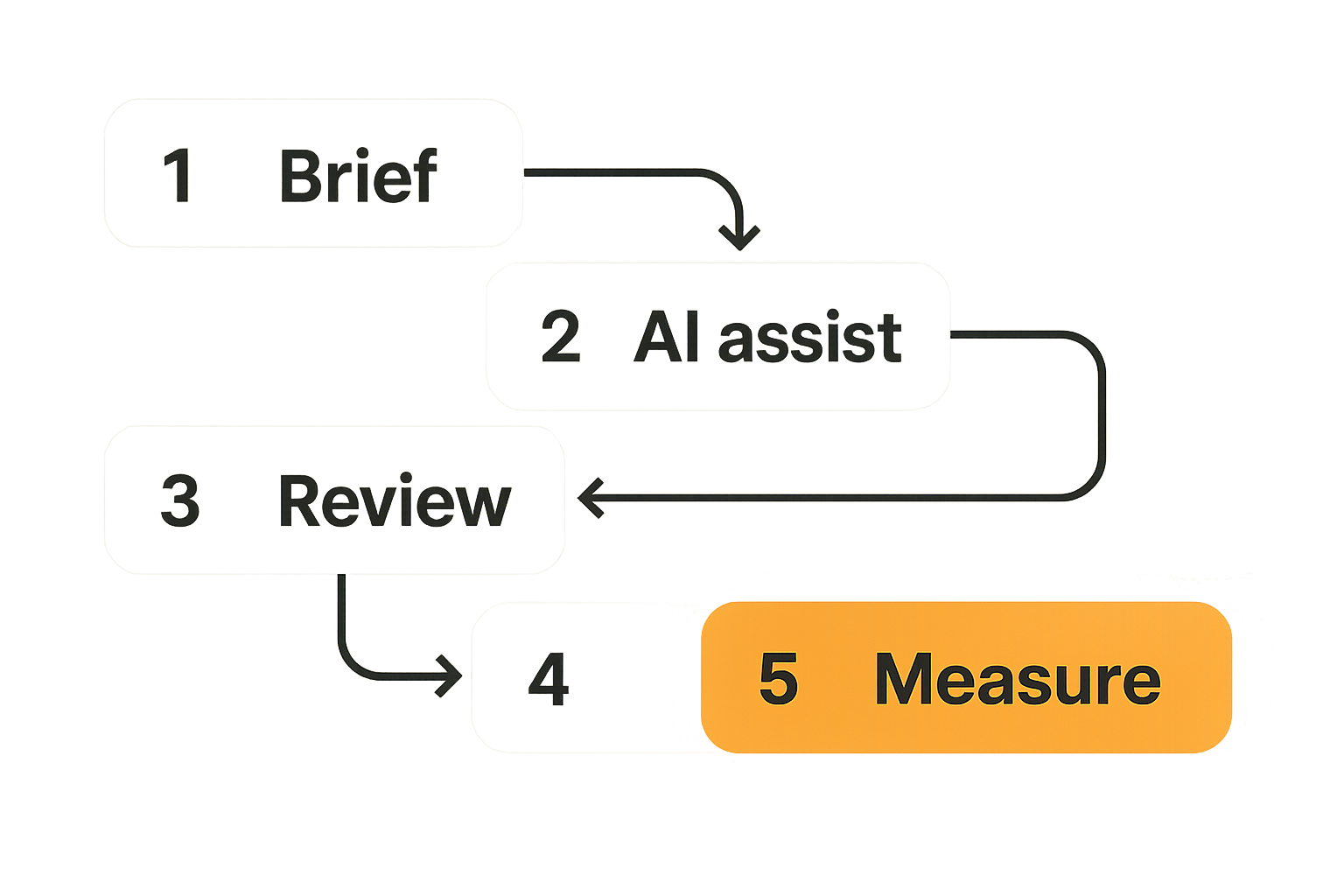
Cloud computing AI content is useful only when it becomes part of how the team works. If it stays as a side tool, it creates parallel production. The writer has one workflow, the editor has another, the SEO lead has a spreadsheet, and the publishing manager has to reconcile the mess.
A useful way to think about it is this: cloud computing provides the shared environment, AI provides the assistive labor, and editorial operations decide what is allowed to move forward.
The cloud changes where work happens
Before cloud-based workflows, a lot of content production lived in local files, one-off documents, email threads, and CMS drafts. The cloud changed the location of work. Briefs, assets, drafts, comments, approvals, analytics, and distribution tasks can now live in shared systems.
That changes the conversation. AI does not need to be pasted into a document manually every time. It can run as a job in the workflow: summarize source material, generate title variants, classify a draft, compare it against a style guide, create social snippets, or prepare newsletter copy.
The mistake teams make is treating cloud computing as storage only. Storage matters, but the larger value is orchestration. The cloud can coordinate events, permissions, versions, compute jobs, and integrations.
AI changes what can be automated
AI is not just a faster keyboard. It can transform content from one format to another. A webinar transcript can become a brief. A brief can become an outline. An approved article can become a newsletter section, a LinkedIn post, and a short-form script.
But transformation is not the same as approval. AI can produce options. Humans decide which options are accurate, useful, on-brand, and safe to publish.
Practical rule: Automate transformations, not accountability.
If a team cannot say who approved the claim, who checked the source, and who released the piece, the workflow is not mature enough for scale.
Editorial control becomes a workflow property
Editorial control should not depend on a senior editor remembering to check every detail manually. It should be built into the workflow.
That means role-based access, required review stages, status changes, content records, revision history, and approval logs. In practical terms, the system should make it harder to skip review than to complete it.
The team at c0mpute.com looks at this from the infrastructure side: compute is only useful when jobs, permissions, and payment or usage boundaries are explicit. The same idea applies to publishing. AI content systems need clear boundaries around what gets generated, reviewed, approved, and distributed.
The stack behind cloud computing AI content
Most content teams do not need to become cloud engineers. But they do need to understand the stack well enough to make operational decisions.
The practical stack has three layers: storage, compute, and APIs. If those layers are vague, the workflow becomes fragile.
Storage holds the source of truth
Every AI publishing workflow needs a source of truth. That source might be a content operations platform, a CMS, a database, or a structured document repository.
The important question is not where drafts are easiest to write. The important question is where the official content record lives.
A content record should include:
- Topic and intent
- Target audience
- Primary keyword and secondary keywords
- Brief and source notes
- Draft versions
- Review status
- Assigned owner
- Approval history
- Distribution assets
- Performance metrics
When this data is scattered, AI cannot help reliably. It will generate from stale context, miss required constraints, or create assets for content that is not approved.
Compute runs the content jobs
Compute is where AI tasks run. That can be a hosted AI model, a cloud function, a background worker, a workflow automation platform, or a dedicated inference service.
For content teams, the key is to separate interactive work from background work. An editor asking for a headline suggestion is interactive. Generating social variants for 300 approved posts is background work.
Those jobs have different requirements. Interactive tasks need low latency. Batch tasks need reliability, retry logic, and cost control.
APIs connect publishing systems
APIs are the connective tissue. They move content between the brief, AI assistant, review queue, CMS, email platform, analytics tool, and social scheduler.
What breaks in practice is the assumption that a copy-paste workflow will scale. It does not. Copy-paste hides state. The system cannot tell which version was approved, which excerpt was published, or which campaign used which headline.
A basic event model is often enough:
content_record:
status: ready_for_editor
owner: managing_editor
ai_tasks:
- generate_outline
- check_style
- create_social_variants
approvals:
seo: pending
editorial: pending
legal: not_required
This does not need to be complex. It needs to be explicit.
Human in the loop is the control layer

Human-in-the-loop AI publishing is often described as a quality philosophy. That is too soft. In production, human review is a control layer.
It decides when AI can suggest, when it can change, when it can publish, and when it must stop.
Where humans must approve
Humans should approve anything that affects trust, positioning, or liability. That includes factual claims, comparisons, legal statements, pricing language, medical or financial guidance, customer quotes, and strategic opinions.
AI can help detect these areas. It can flag claims, identify unsupported statements, and suggest where sources are missing. But approval belongs to a person.
Practical rule: If a sentence could create reputational, legal, or commercial risk, a human owns it.
This is not anti-automation. It is how automation survives contact with the real world.
Where AI can safely assist
AI works well in bounded, reversible tasks. For example:
- Turning a brief into outline options
- Summarizing interview transcripts
- Drafting meta descriptions
- Suggesting internal linking opportunities
- Creating newsletter teaser variants
- Checking for repeated phrases
- Reformatting content for different channels
- Classifying content by funnel stage or topic cluster
These tasks improve throughput without handing over final authority.
The distinction matters. AI assistance should reduce blank-page work and mechanical editing. It should not become an unreviewed publishing engine.
How review lanes prevent bottlenecks
One editor cannot review everything at scale. Teams need review lanes.
A review lane is a structured path based on risk and content type. A low-risk social caption may need light editorial review. A product comparison page may need SEO, legal, and product review. A thought leadership essay may need executive review.
A simple lane model might look like this:
| Content type | AI role | Human review | Approval required |
|---|---|---|---|
| Blog draft | Outline, first draft, SEO checks | Editor and SEO lead | Editorial approval |
| Newsletter | Summaries, subject lines | Newsletter owner | Send approval |
| Product page | Variant copy, clarity checks | Product, legal, editor | Product and legal approval |
| Social posts | Repurposing, formatting | Channel owner | Channel approval |
| Research article | Summaries, structure, citations list | Subject expert, editor | Expert approval |
The point is not bureaucracy. The point is routing. When the system knows the lane, people know what to check.
Designing the AI content workflow
A good cloud computing AI content workflow starts before the draft. If the brief is weak, AI makes the weakness louder.
The mistake teams make is plugging AI into the drafting stage and expecting the rest of the process to fix itself. The better move is to design the full path from intake to measurement.
Start with intake not generation
Intake is where the team decides what should exist. It includes topic selection, audience definition, business goal, search intent, content format, source material, and owner assignment.
Bad intake creates generic output. Good intake gives AI and humans the context needed to make useful decisions.
A practical intake form should ask:
- Who is this for?
- What problem are they trying to solve?
- What should the reader do next?
- What sources or examples must be used?
- What claims must be avoided?
- What channel will this support?
- Who approves the final version?
That last question matters. If nobody owns approval at intake, approval becomes a scramble at the end.
Separate drafting from editing
Drafting and editing are different modes. AI can help with both, but the workflow should not blur them.
Drafting creates material. Editing improves judgment. If the same AI session generates the draft, rewrites the argument, optimizes for SEO, and creates the final version, the team loses visibility into what changed.
A cleaner structure is:
- Generate outline options from the brief.
- Human selects or edits the outline.
- Generate a draft from the approved outline.
- Human edits for argument, accuracy, and voice.
- AI assists with checks and variants.
- Human approves the final version.
This sequence keeps AI useful without letting it silently steer the piece.
Make approvals explicit
Approvals should be states, not comments hidden in a document.
Use clear statuses such as:
- Idea submitted
- Brief approved
- Draft in progress
- Ready for editorial review
- Ready for SEO review
- Ready for legal review
- Approved for publish
- Published
- Needs update
Practical rule: A content workflow is not real until status changes trigger responsibility.
When a draft moves to ready for SEO review, someone should be notified. When legal review is required, publishing should be blocked until it is complete. When the final version is approved, downstream distribution assets can be generated.
Quality gates for cloud computing AI content

Quality gates are the difference between AI-assisted publishing and AI-shaped noise.
A quality gate is a checkpoint that a content item must pass before moving forward. Some gates can be automated. Some require human review. The best systems use both.
Brand and voice checks
Brand voice is hard to enforce through a single prompt. Prompts drift, people improvise, and models produce plausible but bland language.
A better approach is to maintain a living style guide and convert parts of it into checks.
For example:
- Avoid banned phrases
- Match preferred spelling
- Use active voice where possible
- Keep introductions direct
- Avoid unsupported superlatives
- Use product names consistently
- Flag tone mismatches by content type
AI can evaluate a draft against these rules, but editors should still own final voice. The check is a signal, not a verdict.
Fact and source checks
AI content workflows need a strict source policy. The team should know which claims require sources, which sources are acceptable, and which topics require subject expert review.
For practical publishing, divide claims into three buckets:
| Claim type | Example | Review path |
|---|---|---|
| Low-risk editorial claim | Many teams struggle with handoffs | Editor review |
| Business or product claim | This feature reduces review time | Product or marketing approval |
| Regulated or technical claim | This method ensures compliance | Expert or legal review |
The goal is not to source every sentence. The goal is to prevent AI from inventing confidence where the team needs evidence.
SEO and distribution checks
SEO should be part of the workflow, not a patch after writing.
AI can help with search intent analysis, title variants, meta descriptions, schema suggestions, excerpt generation, and internal link recommendations. But SEO still requires editorial judgment. A keyword can fit the article and still make the sentence worse.
Distribution checks should happen before publish. If the article will support a newsletter, social campaign, or creator post, generate those assets from the approved version, not an earlier draft.
This prevents a common failure mode: the blog says one thing, the email says another, and the social post exaggerates both.
What breaks when implementation is loose
Loose implementation does not fail immediately. It usually feels productive for a few weeks. Output increases. People are excited. Drafts appear faster.
Then the defects compound.
Prompt sprawl creates inconsistency
Prompt sprawl happens when everyone builds their own instructions. One writer uses a detailed brief. Another pastes a keyword and asks for an article. A contractor has a different brand prompt. The newsletter operator has another.
The result is not a system. It is a pile of private workflows.
You do not need to ban experimentation. But production prompts should be versioned, shared, and tied to workflow stages.
A practical prompt library includes:
- Purpose of the prompt
- Required inputs
- Output format
- Owner
- Version
- Last reviewed date
- Allowed content types
- Known limitations
This turns prompting from personal craft into operational infrastructure.
Review fatigue lowers quality
When AI creates too much review work, editors become the bottleneck. Worse, they start skimming.
Review fatigue is a design problem. If every piece requires full review, the system has no risk model. If every AI output looks polished, reviewers may miss factual or strategic problems.
The fix is to route work by risk. Low-risk transformations can move through lighter review. High-risk claims need deeper review. Repetitive checks should be automated before a human sees the draft.
Practical rule: Do not use humans as spellcheckers for machine output. Use machines to remove mechanical work before humans make judgment calls.
Untracked AI output creates risk
If the team cannot tell which parts of a piece were AI-assisted, who reviewed them, and what sources were used, it has an audit problem.
This matters for brand safety, client work, regulated industries, and any publisher that cares about trust.
Tracking does not need to be intrusive. It can be simple metadata:
ai_usage:
outline: assisted
draft: assisted
fact_check: human_verified
distribution_copy: generated_from_approved_article
final_approval: editor
The point is to preserve operational memory. Six months later, when a claim is challenged or an article needs updating, the team should not have to reconstruct the entire process from Slack messages.
Cost performance and governance in the cloud
Cloud computing AI content introduces new operating costs. Some are obvious. Some are hidden.
The obvious cost is model usage. The hidden costs are failed jobs, duplicated generation, review overhead, storage clutter, integration maintenance, and slow workflows that waste human time.
Cost is not just model spend
A cheap AI call can become expensive if it produces unusable output. A more expensive workflow can be cheaper if it reduces review cycles.
Track cost at the workflow level, not just the API level.
Useful metrics include:
- Cost per approved article
- Draft-to-approval cycle time
- Number of review rounds
- Percentage of AI outputs accepted, edited, or discarded
- Time from publish to distribution
- Update frequency for existing content
A team that only tracks generation cost will optimize for cheap drafts. That is the wrong unit of value. The unit of value is approved, useful, distributed content.
Latency matters for editors
Editors will not use tools that interrupt their flow. If a style check takes too long, they skip it. If a title generator returns twenty weak options, they stop trusting it.
Latency is not only technical. It is also cognitive. A tool that asks for too many inputs at the wrong time creates friction.
Design AI assists around editorial moments:
- At brief approval, suggest missing context.
- At outline review, identify gaps.
- At draft review, flag claims and voice issues.
- At final approval, generate distribution assets.
- After publish, summarize performance signals.
This keeps AI close to the work instead of becoming another tab.
Governance needs audit trails
Governance is not a policy PDF. It is what the system records and enforces.
At minimum, a mature workflow should track:
- Who created the brief
- Which AI tasks ran
- Which prompt version was used
- Which source materials were attached
- Who edited the draft
- Who approved the final version
- When it was published
- Which distribution assets were generated
This is especially important for agencies, publishers with multiple contributors, and teams using freelancers. The more distributed the team, the more the system needs to carry context.
A practical implementation sequence
The practical question is how to move from scattered AI usage to a reliable publishing operation without rebuilding the whole company.
Start small. Pick one content type, one workflow, and one measurable bottleneck.
Phase one map the workflow
Before automating anything, map the current workflow.
Document the real path, not the ideal one:
- Where ideas come from
- Who approves topics
- How briefs are written
- Where drafts live
- Who reviews what
- How final approval happens
- How publishing is triggered
- How distribution assets are created
- How performance is measured
- How updates are requested
This map will reveal the actual bottleneck. Often, the bottleneck is not writing. It is unclear approvals, missing source material, or last-minute distribution work.
Phase two automate narrow steps
Do not automate the entire workflow first. Automate narrow, repeatable steps.
Good first automations include:
- Generate outline options from approved briefs
- Summarize interview transcripts
- Flag missing sources
- Check drafts against a style guide
- Generate meta descriptions from approved drafts
- Create newsletter blurbs after publish approval
- Produce social variants from the final article
Each automation should have an owner, success criteria, and fallback path.
If the AI task fails, what happens? Does the editor retry? Does the workflow continue? Is a human notified? These operational details matter more than the demo.
Phase three measure and tune
Once the workflow is live, measure the system.
Do not rely on vague feedback like the drafts are better. Track operational signals:
| Signal | What it tells you | Possible action |
|---|---|---|
| High discard rate | AI output misses the brief | Improve intake or prompt |
| Many review rounds | Approval criteria are unclear | Add quality gates |
| Slow SEO review | SEO is too late in workflow | Move SEO checks earlier |
| Distribution delays | Assets are created too late | Generate after approval |
| Frequent post-publish edits | Review gates are weak | Add fact or expert review |
Measurement closes the loop. Without it, the workflow becomes opinion-driven.
What works and what fails
There is a pattern across content teams that make AI useful without losing control. They are not trying to replace the editorial team. They are trying to remove the repetitive work that slows the editorial team down.
That difference drives almost every good implementation decision.
What works in production
What works is boring in the best way.
- Structured briefs
- Shared prompt libraries
- Role-based review lanes
- Human approval for risky claims
- AI checks before human review
- Approved-source repositories
- Distribution assets generated from final copy
- Workflow metrics tied to approved output
These practices do not depend on a specific model. Models will change. The workflow should survive those changes.
What fails in production
What fails is usually over-automation without ownership.
Common failures include:
- Publishing AI drafts with light review because they sound polished
- Letting every contributor invent prompts from scratch
- Generating channel assets from unapproved drafts
- Treating SEO as keyword insertion instead of intent matching
- Asking one editor to review unlimited AI output
- Failing to record AI usage and approval history
- Optimizing for volume while ignoring updates and performance
The problem is not that AI is bad at content. The problem is that the team has not defined the content system.
The useful middle path
The useful middle path is AI-assisted, human-led, cloud-coordinated publishing.
AI handles repetition. Humans handle judgment. Cloud systems keep the work shared, trackable, and integrated.
A simple comparison helps:
| Approach | What it optimizes for | What breaks |
|---|---|---|
| Manual-only workflow | Control and craft | Slow output, repeated work, poor reuse |
| AI-only workflow | Speed and volume | Trust, accuracy, brand voice, accountability |
| Human-led AI workflow | Throughput with control | Requires process design and ownership |
The third option is not the flashiest. It is the one most likely to keep working after the novelty wears off.
Where bl0ggers.com fits in the cloud computing AI content workflow
Cloud computing AI content needs a place where AI support and editorial control meet. For many content teams, that is the missing layer between raw AI tools and the publishing calendar.
The goal is not to add another disconnected app. The goal is to give teams a workflow where briefs, drafts, review, approvals, distribution, and measurement stay connected.
Fit for content teams
bl0ggers.com fits teams that want more output but do not want AI content floating outside the editorial process.
The useful product pattern is straightforward:
- Start from a clear brief
- Use AI to accelerate structured steps
- Keep humans in review lanes
- Apply quality gates before publish
- Generate distribution assets from approved content
- Track what happened so the next cycle improves
That is the architecture content teams actually need. Not just a chat box. Not just a CMS field. A workflow.
Fit for publishers and newsletters
Publishers and newsletter operators have an additional problem: cadence. The machine has to run every week, sometimes every day.
That makes consistency more important than occasional brilliance. A workflow that captures source material, supports repeatable review, and turns approved ideas into multiple channel assets is more valuable than a one-off draft generator.
For newsletter teams, the biggest win is often not writing the newsletter from scratch. It is summarizing approved posts, selecting the right angle for the audience, preparing subject lines, and keeping the send aligned with the published article.
For publishers, the win is operational memory. You know what was approved, what was distributed, what performed, and what should be updated.
Try bl0ggers.com
bl0ggers.com helps content teams use cloud computing AI content workflows to increase output while keeping editorial review, approvals, and measurement in place. Try bl0ggers.com